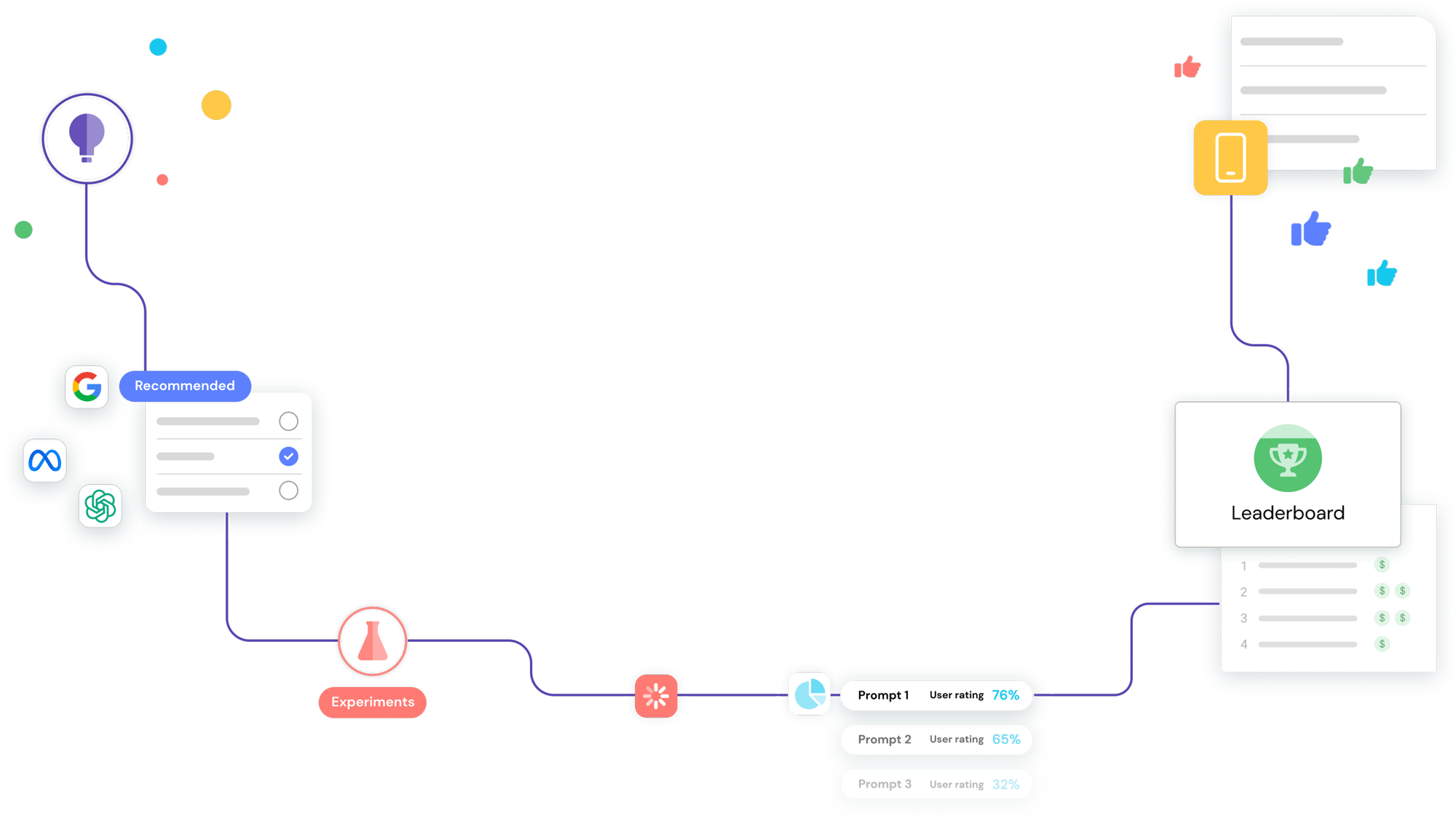
Hit the ground running
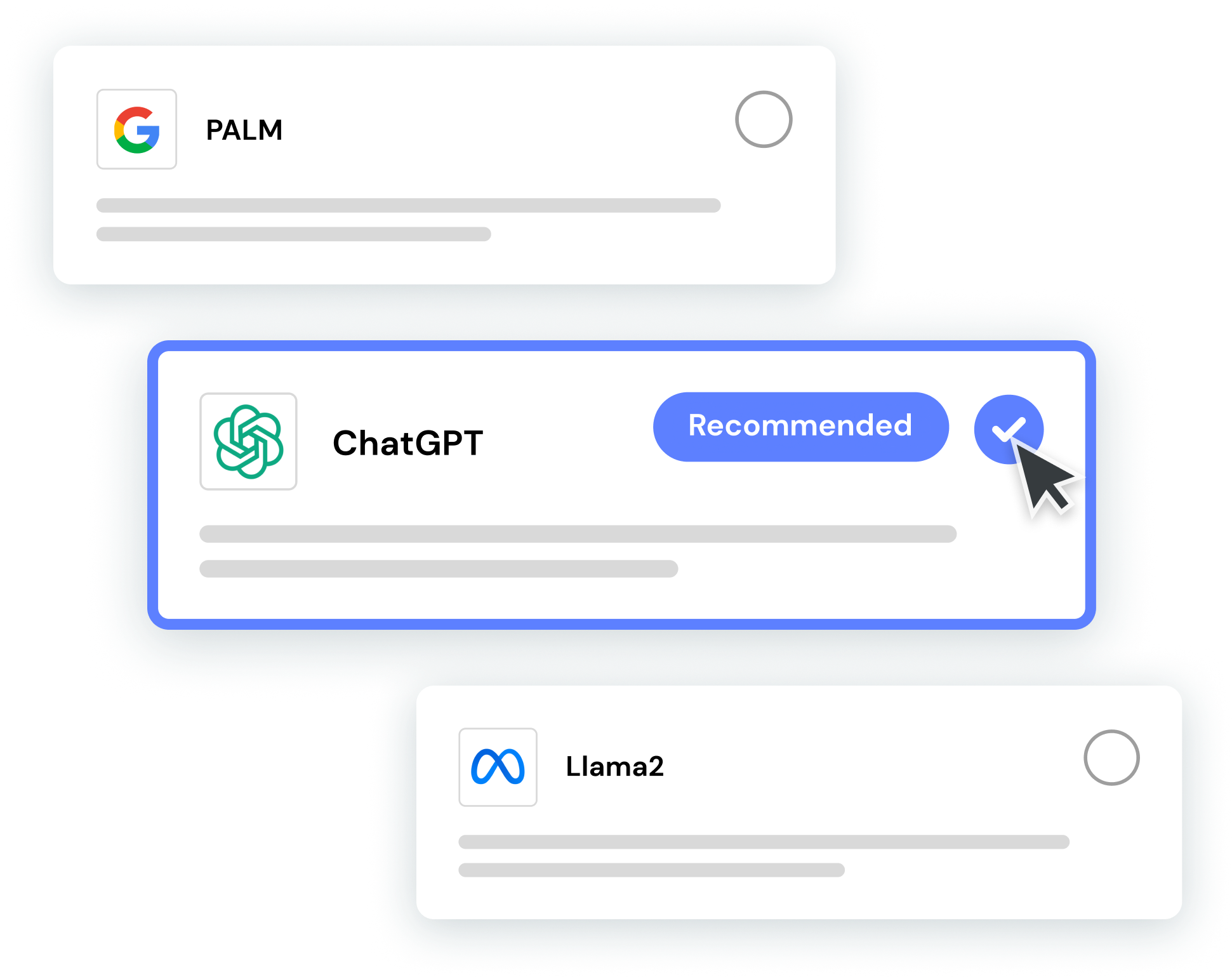
Get everything you need to start customizing LLMs and prompts immediately—no PhD required. Starter Kits with model, prompt, and dataset suggestions matched to your use case allow you to begin testing, evaluating, and refining model outputs right away.
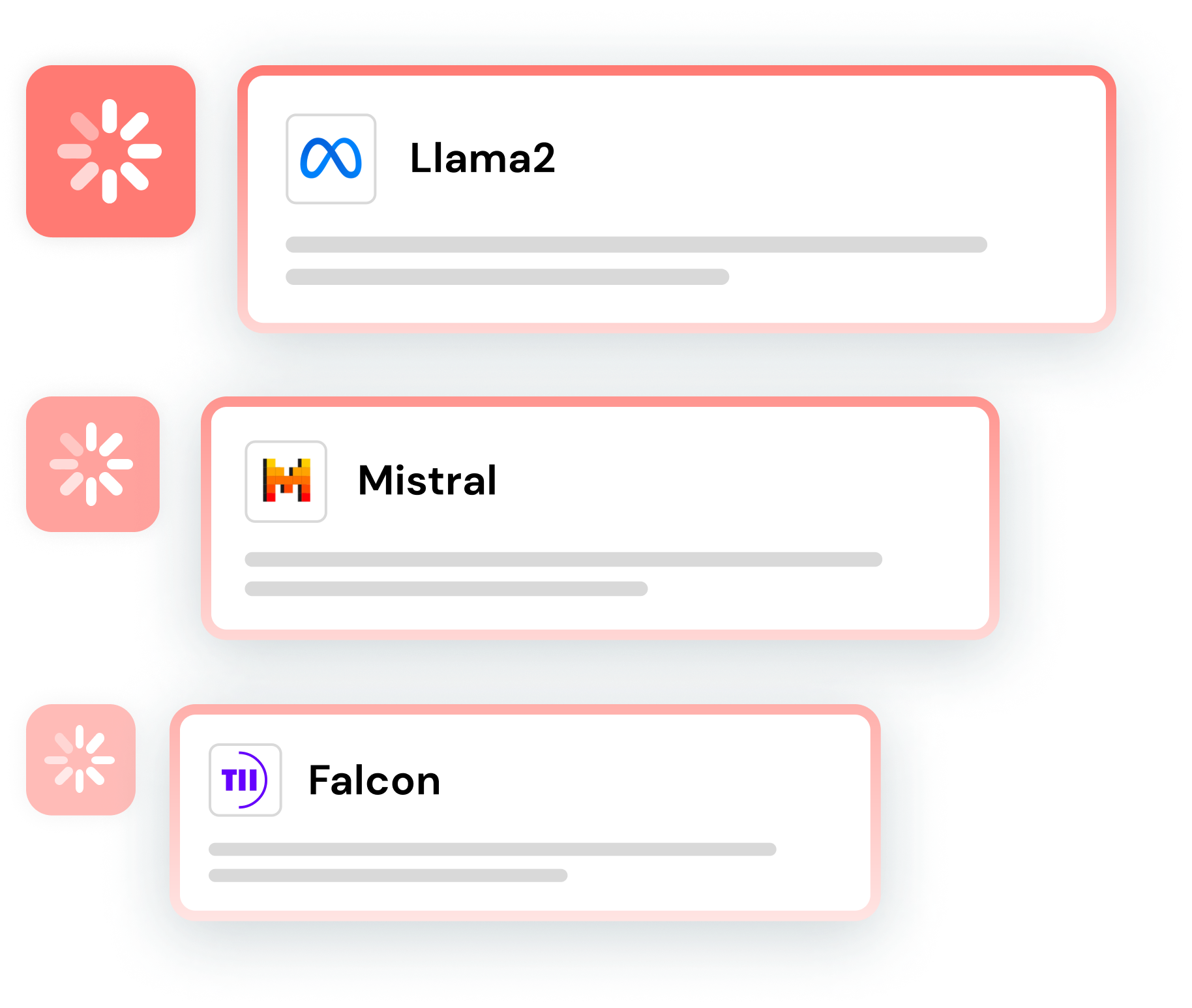
Accelerate experimentation
Experiment with multiple models (proprietary and open-source), prompts, and techniques simultaneously to speed up the iteration process. Automated testing and evaluation and AI-powered prompt and refinement suggestions enable you to run many experiments at once to quickly achieve high-quality results.

Leverage all your expertise
Verta’s easy-to-use platform empowers builders of all tech levels to achieve high-quality model outputs quickly. Using a human-in-the-loop approach to evaluation, Verta prioritizes human feedback at key points in the iteration cycle to capture expertise and develop IP to differentiate your GenAI products.
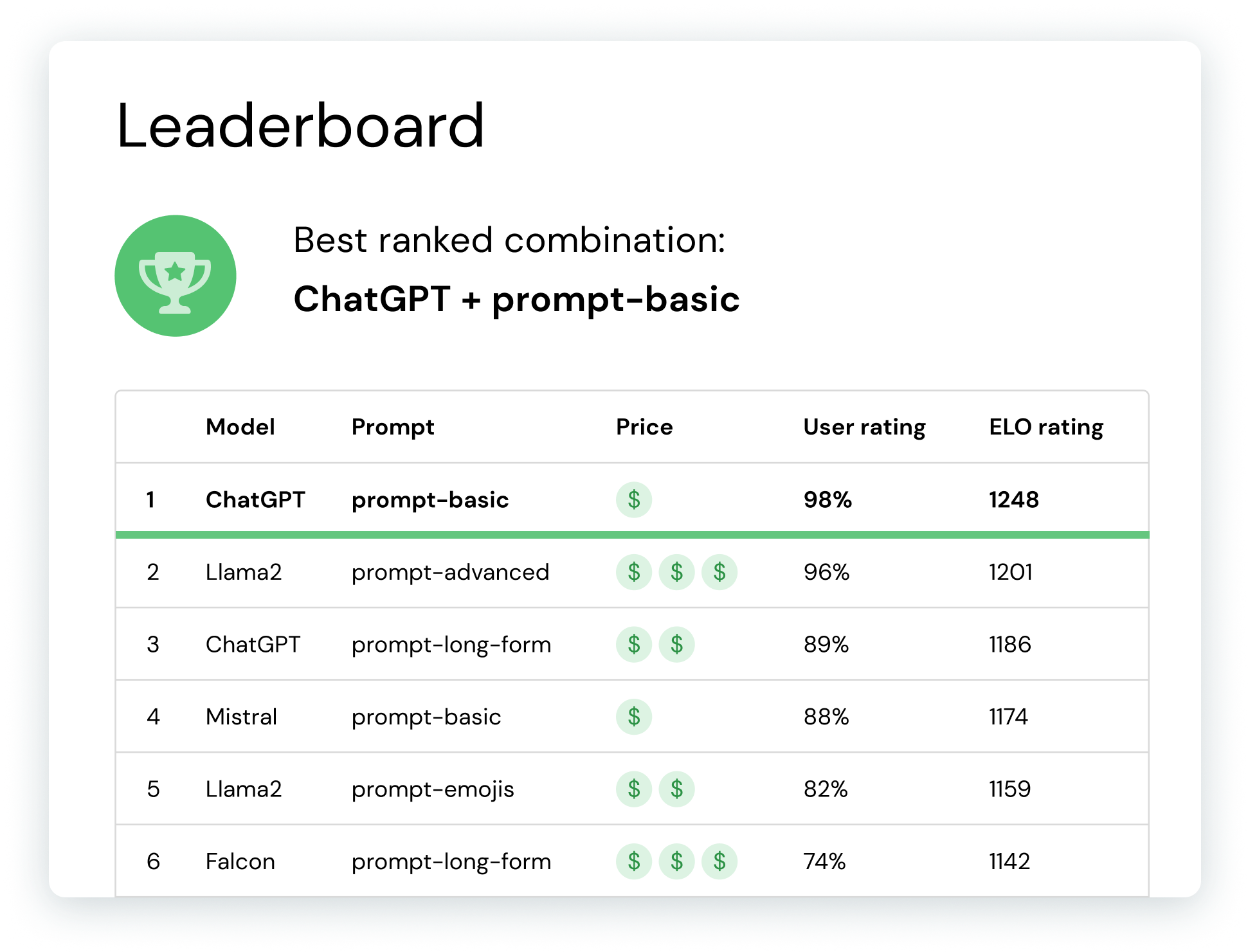
Compare and share results
Easily keep track of your best-performing options from Verta’s Leaderboard. Evaluate and validate outputs, track metrics, compare versions, share learnings and feedback, and approve applications for release — all from one location.

Track performance in the wild
Once deployed, continue to improve application performance with feedback from the experts—your users. Automatically collect and monitor valuable user feedback to further refine results and enhance user experiences.

"Verta has accelerated our GenAI application development and reduced our development costs which as a startup has been extremely helpful. Going from zero to 1 with GenAI has never been easier thanks to Verta!"
Brian Barela, Product Manager

“Before Verta, classifying our entire data universe would take days. Verta helped us redo our entire universe in 20 minutes.”
Jenn Flynn, Principal Data Scientist
“We are impressed with Verta’s scalable and feature-rich model management platform. And the team goes above and beyond to provide excellent customer support.”
QP Hou, Senior Engineer, Core Platform

“Verta freed up a lot of time for my team members to actually spend more time doing exploratory modeling as opposed to having to deal with the heavy engineering aspect of maintaining models.”
Alex Quintero, Director of Data Science
