This blog post is part of our series on Serverless Inference for Machine Learning models accompanying our KubeCon 2020 talk: Serverless for ML Inference on Kubernetes: Panacea or Folly? We'll be hosting a live replay on December 2nd at 2 PM ET for anyone who missed it.
As builders of an MLOps platform, we often get asked whether serverless is the right compute architecture to deploy models. The cost savings touted by serverless seem extremely appealing for ML workloads as for other traditional workloads. However, the special requirements of ML models as related to hardware and resources can cause impediments to using serverless architectures. To provide the best solution to our customers, we ran extensive benchmarking to compare serverless to traditional computing for inference workloads. In particular, we evaluated inference workloads on different systems including AWS Lambda, Google Cloud Run, and Verta.
In this series of posts, we cover how to deploy ML models on each of the above platforms and summarize our results in our benchmarking blog post.
- How to deploy ML models on AWS Lambda
- How to deploy ML models on Google Cloud Run
- How to deploy ML models on Verta (coming soon)
- Serverless for ML Inference: a benchmark study (coming soon)
This post talks about how to get started with deploying models on AWS Lambda, along with the pros and cons of using this system for inference.
What is AWS Lambda?
AWS lambda is AWS’s serverless offering and arguably the most popular cloud-based serverless framework. Specifically, AWS Lambda is a compute service that runs code on demand (i.e., in response to events) and fully manages the provisioning and management of compute resources for running your code. Of course, as with serverless offerings, it only charges you for the time Lambda is in use. The main appeal of AWS Lambda is the ease of use on multiple levels: first, the developer doesn’t have to worry about infrastructure or resources and can focus only on business logic; second, the developer doesn’t need to maintain infrastructure, so upgrades, patches, and scaling is fully taken care of; and finally, as mentioned prior, using Lambda can be cheaper in terms of total cost of ownership (TCO).
In this blog, we will describe how to run ML models on AWS Lambdas. In particular, we will demonstrate how to run DistillBERT on Lambda.
Note that this blog post focuses on the ML-specific aspects of deploying to AWS Lambda. For a primer on how to deploy to Lambda in general, check out these tutorials: Hello World with console, Hello world with AWS SAM.
Step 1: AWS Setup
First, go to the AWS Console and perform the setup for Lambda. In our case, we choose to trigger the Lambda via an HTTP request to an API gateway.
API Gateway provides a HTTP POST endpoint which passes the request body to the actual Lambda function. The logs and metrics from the gateway and Lambda are stored in AWS CloudWatch.
Step 2: Write your inference code!
For this example, we use the DistillBERT question and answer model from HuggingFace. Our inference function performs the following actions:
- Initialize the Lambda with the relevant libraries such as HuggingFace transformers and torch
- Load the relevant model from the transformers library
- Make a prediction on the input data
Note that the model was serialized by the following two lines of code.
Now that the code is ready, we upload the Lambda function to an S3 bucket as a deployment package and we are good to go.
Step 3: Let’s give it a spin
Our setup above looks almost perfect but we immediately hit a resource limitation. The DistillBERT model is 253MB and the PyTorch + HuggingFace libraries and their dependencies (support for only cpu) are 563MB uncompressed. These are well outside the limits for AWS (relevant ones shown below, full list at here).
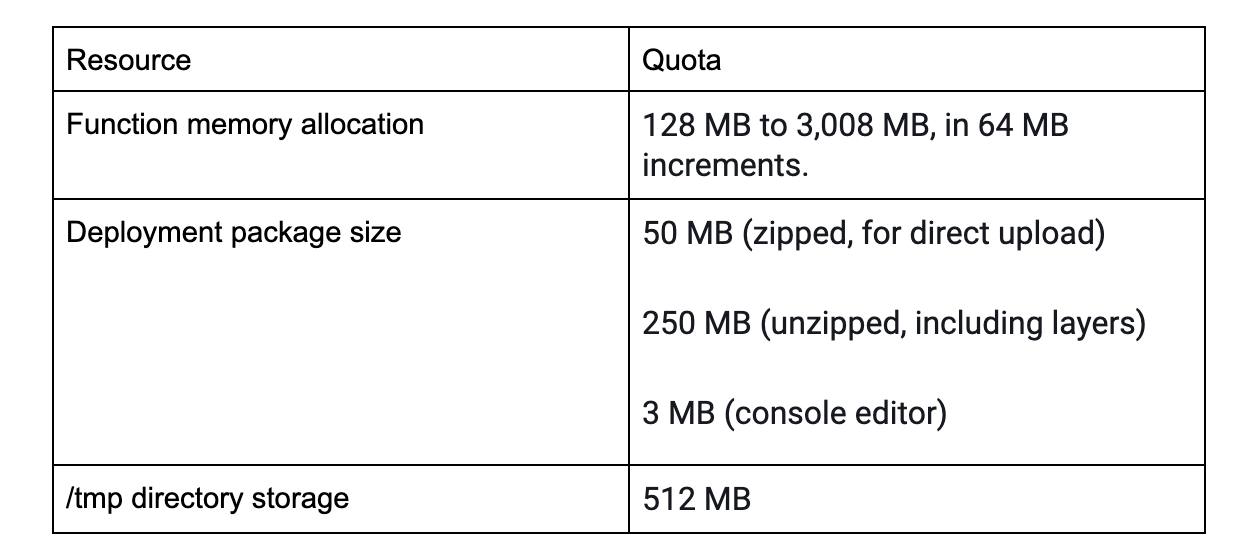
It looks like we cannot deploy the model on AWS Lambda.
Step 4: Let’s fix that
Now that we understand the restrictions in using DistillBERT on Lambda, let’s try to fix them by reducing the size of our models and or libraries or the way that we load the model into the lambda.
Optimization 1: Download the model into memory
First, we choose to download the model into memory vs. disk when the lambda boots up. This allows us to work on the 3GB memory buffer and use memory to simulate disk. For this approach, we download the model on our local machine (via save_pretrained) and upload it to S3. Then when the Lamda starts up, we will download the model into memory. In Python, this is feasible since the model is one big binary and many python libraries can operate with streams as opposed to files. The snippet below shows how to do this:
Optimization 2: Reduce library size by deleting modules that are not used
Downloading the model into memory was easy. When we get to Python libraries, things get trickier. As mentioned before, libraries required for this model amount to 563MB on disk uncompressed. Most of this size comes from binaries with C extensions for Python. Removing those files and placing them in memory is a non-trivial task, since we’d have to change how python module loading works.
Instead, we used a technique similar to this tutorial: delete everything you know you won’t need. It takes a bit of trial and error to get this right. In the case of this model, the following was enough to get the package to fit in the 512MB of space on /tmp.
We then compress the requirements and the compressed file amounts to 124MB, which unfortunately doesn’t fit in the 50MB compressed limit for the package. It also wouldn’t’ fit in the 250MB uncompressed limit either. So we have to do yet another layer of manipulating the packages to place them in exactly the right place and use them in the right way.
In this case, we uploaded the compressed artifact into S3 and, at the start of the function, we download it (into memory since it won’t fit in disk together with its uncompressed version!), unzip to /tmp and alter sys.path to change where python looks for packages. This is done via the following snippet:
Voila!
Now that we have everything in the right place (either in disk or memory), we can actually load the libraries, models and run predictions! It does take a while to spin up a new worker since a lot of work needs to be done by our customized code and can’t be cached by Lambda to use in other workers.
So should you use AWS Lambdas for ML inference?
So now we have our model deployed on AWS Lambda. But the big question is should you?
The complexity of running a ML model on Lambda is directly proportional to the size of the model and its dependencies. A very simple model with dependencies in a few MBs can be easily deployed on lambda in a matter of minutes. However, as the size of the model and its dependencies increase, the problem of deploying to Lambda becomes progressively harder. It involves hours of trial and error to get the model + dependencies to fit within the constraints imposed by AWS. Moreover, this effort must be repeated for every model that is deployed.
In addition, from a performance standpoint, the optimizations to fit into the Lambda resource constraints, have side effects during execution. In our case reading and uncompressing the dependencies to `/tmp` or reading the compressed model from s3 to memory impose an overhead on the cold start latency of the lambda. This overhead is in addition to the typical cold-start overhead for serverless systems that we evaluate in our benchmarking blog (below).
Finally, when deploying or making changes to any of the set up above via the AWS Console does not provide any audit trail or versioning capabilities, making updates error-prone and burdensome (this can be mitigated via an automated CI system).
So our verdict:
- If your model and dependencies are small, deploying to AWS Lambda makes sense
- If your model is static or if you only ever deploy one model, AWS Lambda makes sense
- If your model is large (typically any real-world deep learning model), Lambdas are not very appealing due to the large overhead of optimizing the model and dependencies for Lambda
- If you will update your model fairly frequently or deploy many models, the overhead of optimizing each model to run in AWS Lambda becomes many-fold
- From a usability standpoint, it’s unrealistic to expect someone without substantial software engineering experience to optimize models for AWS Lambda
- Similarly, in a low latency setting, the performance overhead of the optimizations at runtime can be unacceptable
Curious about alternatives for AWS Lambda? Check out our blog on Google Cloud Run and, of course, check out Verta!
Stay tuned for our summary benchmarking blog post comparing different serverless systems for ML inference.
About Verta:
Verta provides AI/ML model management and operations software that helps enterprise data science teams to manage inherently complex model-based products. Verta’s production-ready systems help data science and IT operations teams to focus on their strengths and rapidly bring AI/ML advances to market. Based in Palo Alto, Verta is backed by Intel Capital and General Catalyst. For more information, go to www.verta.ai or follow @VertaAI.
Subscribe To Our Blog
Get the latest from Verta delivered directly to you email.


