
In Generative AI, particularly for Large Language Model (LLM) applications such as question-answering systems and chatbots, the Retrieval-Augmented Generation (RAG) architecture is fast emerging as a gold standard. RAG combines data retrieval (searching through large datasets to find relevant information) and text generation (creating text based on the retrieved data) to enhance AI output. This hybrid approach generates more accurate, and contextually relevant text by leveraging information beyond its initial training data.
The key to unlocking the full potential of RAG lies in its effective evaluation. In this blog post, dive into RAG evaluation, exploring the key steps, criteria, and metrics involved.
Understanding RAG evaluation
RAG evaluation is a multi-step process that involves assessing the quality, relevance, and performance of the generated responses. Unlike LLM evaluation, which focuses primarily on text generation, RAG evaluation requires an additional layer of scrutiny due to its data retrieval component. The evaluation process can be broadly divided into two main steps:
Document Retrieval Evaluation: This step focuses on evaluating the quality of the retrieved information or context. It involves assessing the relevance, completeness, and accuracy of the retrieved data.
Generated Response Evaluation: Here, the focus shifts to evaluating how well the LLM has generated a response based on the retrieved information. This involves assessing the coherence, factuality, and relevance of the generated text.
Components impacting RAG evaluation
Each component in RAG architecture has an impact on the quality and performance and hence should be considered carefully.
- Knowledge base: High-quality, well-curated data sources of your knowledge base are essential for accurate and reliable answers generated by the RAG system.
- Indexing: Indexing involves tokenization and vectorization of text data, creating numerical vectors stored in a database. Efficient indexing increases the relevance of retrieved data.
- Context search: Also known as Retrieval, is the efficiency and preciseness of how the system searches and retrieves information from the knowledge base (vector embeddings) directly impacts the usefulness of the retrieved information.
- Prompt design: Well-designed prompts can significantly enhance the model's ability to produce relevant and accurate responses. (Also, very useful in automating the end-to-end pipeline)
- LLM: The effectiveness of the LLM in synthesizing and integrating context information into the response.
Evaluation metrics to consider
When evaluating RAG applications, here are some of the useful metrics to consider:
.png?width=732&height=732&name=Rag%20metrics%20chart%20(1).png)
How to Evaluate a RAG Application
To evaluate a RAG application effectively, follow these steps:
Create an evaluation dataset: Build a benchmark dataset of examples (question, context, answer).
- Make sure example questions are covering real scenarios and are relevant.
- For every example questions identify relevant sections from the available documents. This will help your test if the context (all relevant information) is accurately identified to generate a response.
- Draft expected answers for each example question that can be used as the ground truth answer
You should involve SMEs (Subject Matter Experts) to create questions, context and groundtruth at the beginning of the project. Additionally, explore an automated approach to build a synthetic dataset of questions and associated contexts by using a reference LLM (e.g. GPT-4).
Benchmark: Compare the responses generated by the RAG application with the groundtruth context and response.
Benchmarking can be done in several ways:
- Manual evaluation: Have subject matter experts or trained annotators review the retrieved information for each query and rate them on various predefined criterias like relevance, completeness, accuracy etc.
- Automated evaluation: Use a judge LLM or other natural language processing (NLP) techniques to compare the semantic similarity between the query and the retrieved documents.
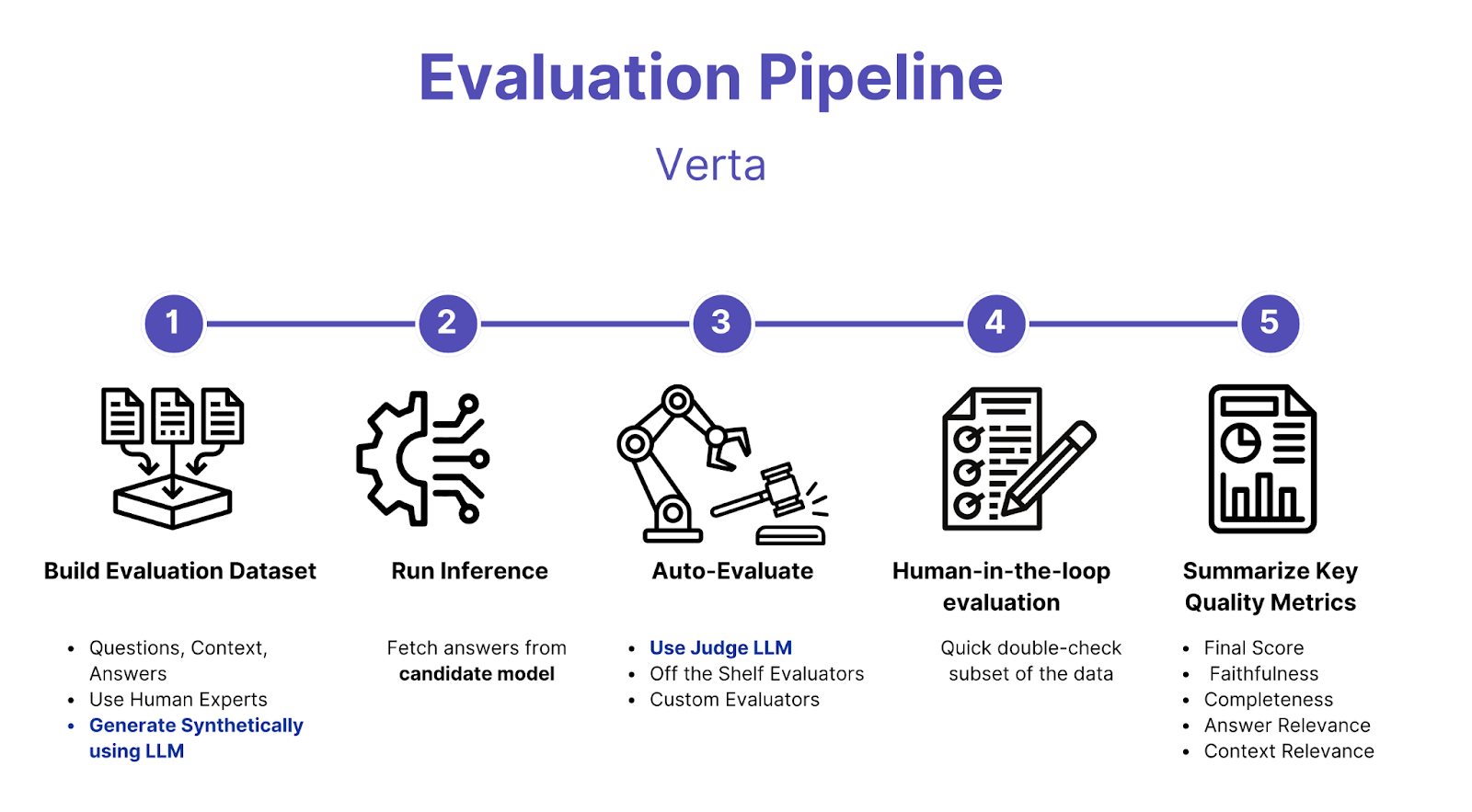
Build an evaluation pipeline: As you start scaling your development workflow, build an evaluation pipeline.
- Build a golden dataset with questions and answers. The dataset can be created both by human experts or synthetically using another LLM.
- For more complex metrics like faithfulness, groundedness etc, it is advisable to use manual evaluation
- Write evaluators to compare the results of the golden dataset with the actual results to compute metrics like relevance, accuracy, conciseness etc. There are several open source evaluators available out of box that you can use.
- A judge LLM can also be used to compare the golden results with actual results and compute evaluation metrics
Conclusion
Evaluating RAG systems is essential to iterate and optimize their performance in generating accurate and relevant responses. Through assessing both document retrieval and response generation, using metrics like Hit Rate, MRR, Context Relevance, along with Accuracy, Groundedness, and Faithfulness, we can gauge a RAG system's effectiveness. Effective evaluation combines expert review and automated methods, ensuring RAG systems meet high standards of reliability and relevance.
Subscribe To Our Blog
Get the latest from Verta delivered directly to you email.


