
AI and ML have arguably become the backbone of today’s most valuable and game-changing tools across industries. Companies that adopt and deploy machine learning solutions to customers’ problems win markets by providing better customer and user experiences. However, operationalizing machine learning and going from prototype to production is a pervasive challenge.
Today, an AI product team’s biggest struggle is the inability to efficiently operationalize models at scale and deliver the ML capabilities that make a real difference. Making machine learning prototypes is easy, but deploying smart applications is not. There’s no shortage of bottlenecks, but some of the most common issues include: not having the know-how to properly deploy models more efficiently, significant development and maintenance costs, the reliability and SLA considerations that need to be taken into account, and needing to build machineries to integrate new services into production (while avoiding breaking things).
Verta simplifies the deployment process and inference for batch, realtime, and streaming ML applications. Because our platform is based on Kubernetes, we offer the ability to run models in containers among other modes of model deployment. Once the model is deployed, the Verta platform automates provisioning and management of resources and infrastructure. Our auto-scaling capabilities allow the system to adapt to changing query loads as well, and there is always at least one copy of a deployed model running and can instantly serve requests.
What does this mean for your business? It means your scarce and talented machine learning specialists spend less time on getting their models to work, and focus on what they do best — building amazing models. The tedious and time intensive infrastructure work is handled by the Verta platform and recruits other members of your team —from software engineers to DevOps — to help productionize your ML solutions.
In this blog, we’ll show you how to run models on Verta, with a focus on how to run a TensorFlow model with MNIST data. The MNIST dataset of handwritten digits has 784 input features (pixel values in each image) and 10 output classes representing numbers 0–9.
Getting Started: Gaining Access to the Verta Difference
To gain access to the Verta platform and experience the difference it brings first hand, you’ll need to first complete two easy steps:
- Contact us to get trial access
- Set up your Python client and Verta credentials here
Once you’ve completed the registration portion of the process, you can get to deploying. This also requires two easy steps:
Step 1: Register the model
Let’s go ahead and train a TensorFlow model with MNIST dataset for digit classification and register it. To register a model version, we’ll need to give it a name, version id, the set of artifacts that belong to the model, and the environment. Model artifacts usually include the weights file or pickle file with the serialized model.
import osimport TensorFlow as tf# import verta client# restart your notebook if prompted on Colabtry:import vertaexcept ImportError:!pip install verta# setup verta credentialsimport os# Ensure credentials are set up (contact us if you need credentials)os.environ['VERTA_EMAIL'] = "XXXXXX"os.environ['VERTA_DEV_KEY'] = "XXXXXX"os.environ['VERTA_HOST'] = "XXXXXXXXXXXX"from verta import Clientclient = Client(os.environ['VERTA_HOST'])# Train your modelmnist = tf.keras.datasets.mnist(x_train, y_train), (x_test, y_test) = mnist.load_data()x_train, x_test = x_train / 255.0, x_test / 255.0model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.2),tf.keras.layers.Dense(10)])loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)model.compile(optimizer='adam',loss=loss_fn,metrics=['accuracy'])model.fit(x_train, y_train, epochs=5)# Register a model with Vertaregistered_model = client.get_or_create_registered_model(name="mnist", labels=["computer-vision", "TensorFlow"])from verta.environment import Pythonmodel_version = registered_model.create_standard_model_from_keras(model, environment=Python(requirements=["TensorFlow"]), name="v1")
Step 2: Deploy the model
In order to serve a model, Verta requires that its class expose __init__() and predict() methods. Other than that, the model code can execute arbitrary logic. Within Verta, a "Model" can be any arbitrary function: a traditional ML model (e.g., sklearn, PyTorch, TF, etc); a function (e.g., squaring a number, making a DB function etc.); or a mixture of the above (e.g., pre-processing code, a DB call, and then a model application).
You can use our web UI for a one click deployment or use API or client SDK.
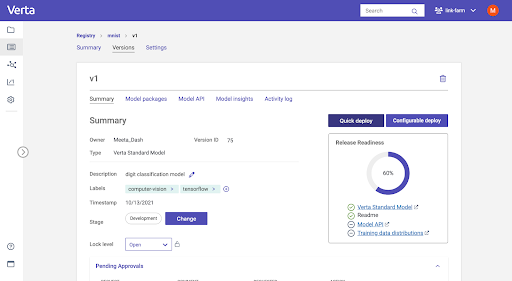
Here’s an example of deploying using the python client. We can now specify the endpoint (i.e., URL) where you would like the model to deploy and optionally specify resource requirements for the model. With that setup in place, we’re ready to deploy.
# Deploy a modelfrom verta.endpoint.autoscaling import Autoscalingfrom verta.endpoint.resources import Resourcesautoscaling = Autoscaling(max_replicas=20, min_scale=0.5, max_scale=2)resources = Resources(cpu=1, memory="1G")mnist_endpoint = client.get_or_create_endpoint("mnist")mnist_endpoint.update(model_version, autoscaling=autoscaling, resources=resources, wait=True)
At this point, in the background, Verta has been busy. It’s gone off and fetched the relevant model artifacts, added scaffolding code and packaged the model into a server, created Kubernetes services and other associated elements to run and scale the model, and it has provisioned this endpoint URL. All of this has occurred without any code surgery, special handling of large model files, or interacting with Kubernetes directly.
When your endpoint is live you can review the endpoint status, monitor operational metrics and view logs in the web UI.
If you’re a machine learning scientist, you can hand your model’s endpoint off to the engineer who is integrating the model into your production services.
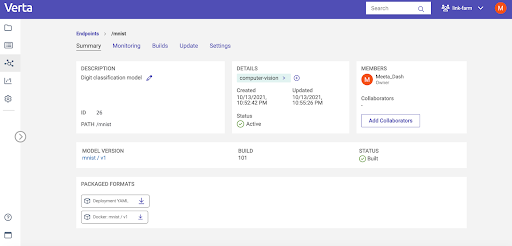
Running Predictions in Verta Model Deployment
When the endpoint is live and active, you can send prediction requests. You can make predictions via the Python client, via cURL, or via the REST library.
# Send prediction requestsdeployed_model = mnist_endpoint.get_deployed_model()deployed_model.predict([x_test[0]])
The output for MNIST classification includes 10 output classes representing numbers 0-9 and your model prediction should look similar to this;
[[-4.107306957244873,
-7.405611038208008,
-0.5806922912597656,
4.529562950134277,
-13.215812683105469,
-4.544963836669922,
-20.606962203979492,
12.196496963500977,
-4.0695109367370605,
-1.2950152158737183]]Alternately this is an example of a curl command that you can run to send prediction requests to the model. Verta offers different mechanisms to secure endpoints including access tokens.
curl -H "Access-token: XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXX" -X POST https://customer.app.verta.ai/api/v1/predict/mnist -d [[JSON INPUT DATA]] -H "Content-Type: application/json"Comprehensive Model Deployment Platform
In addition to the online serving workflow that we just discussed, Verta offers a breadth of deployment options and safe model operation practices:
- Kafka Integration: Verta supports streaming workloads via Kafka. With Verta as the serving platform, the models essentially will be able to take their inputs from a Kafka topic and push their outputs to a Kafka topic
- Batch predictions: You can run batch inference in the platform and easily transition a model from batch to online or vice versa
- Ecosystem deployment: You can import a Verta model package and deploy it in another platform (e.g. Spark, Flink etc.)
- New model deployment: Safely roll out new models via processes like canary roll-out
- Track performance: Operational metrics are available in the platform or can be funneled to the APM platform of your choice.
- Track activity: Platform access logs and Model I/O logs are all captured and make available to the users
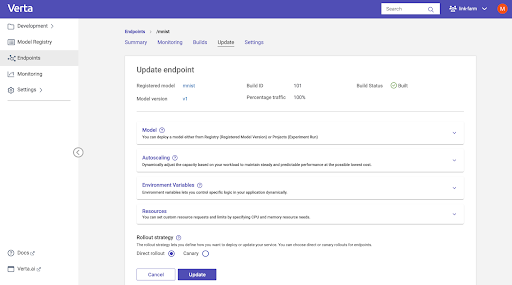
A Modern Approach to a Modern Problem
Here at Verta, we’re helping professionals catch up to the power of technology with one-click deployment options for quickly rolling out new models without worrying about DevOps and release tools. Our approach abstracts away the details of the infrastructure while allowing the user the ability to use the required amount of resources to run a model and instantly deploy models.
With Verta, you can establish a consistent, safe and reliable release process for your real-time, batch and streaming models while all the operational complexities, like scaling, reliability, monitoring and logging, are automatically taken care of.
If you’d like to see first-hand how the magic happens, we invite you to connect with us for a demo.
Subscribe To Our Blog
Get the latest from Verta delivered directly to you email.


