
At Verta, we ran our first ModelDB 2.0 webinar last week and it was a lot of fun. This blog post is a recap of the hands-on tutorial part of the webinar. For the full webinar content, check out the webinar recording on the Verta Youtube channel and the slides on Slideshare.
What is ModelDB?
.png?width=10912&name=model%20versioning%20(1).png)
ModelDB is an open-source model versioning, metadata, and experiment management system originally developed at MIT’s Computer Science Department and now maintained by Verta.ai.
ModelDB 2.0, the latest release of ModelDB, brings git-like versioning to ML models (and all types of analytical products). By applying versioning to the ingredients of ML models, in particular, code, data, config, and environment, ModelDB captures all the components necessary to reproduce a model. Best of all, ModelDB requires no change to your data science/ML workflow. It can be integrated into a Jupyter notebook or used from the command-line.
Read more about the architecture of ModelDB and the motivation behind its design here.
The Task: Modeling the Census Income Dataset
For our first ModelDB walkthrough, we used a simple tabular data example. Specifically, we use the census income dataset that has been lightly preprocessed to make modeling easy. The task here is to build a model to predict a person’s income level (<$50K or > $50K) given demographic information such as age, sex, education, zip code, etc.
We will build a few simple models and focus on making all of our models reproducible by versioning them with ModelDB.
1. Basic Notebook without Versioning
For this tutorial, we put together a simple notebook that builds different models on the census income dataset. Let’s go over the key parts of this notebook.
a) We download the census data and check its contents.
b) We build a few scikit-learn models and cycle through a grid of hyperparameters
We then pick the best model. That’s it — simple and straightforward.
2. What's the issue?
Now, if you’re like most data scientists (including myself!) you aren’t versioning your models beyond naming your different notebooks in awkward ways or at most a spreadsheet with your experimentation details.
But this solution is inadequate when building hundreds of models, answering regulatory questions, or sharing work. Here’s where a purpose-built model versioning system like ModelDB really shines.
3. Setting up ModelDB
ModelDB is available under the Apache 2 open-source license and can be set up in a variety of ways as described here and on the ModelDB Git Repo.
The easiest way to set up ModelDB is to run:
4. Versioning our models with ModelDB
a) First, install the verta library and perform the basic setup by creating a ModelDB project and an associated repository.
b) Next, instrument our notebook to version the ingredients for our model, including the code, the data, config, and environment, all via a library.
And we're done.
5. What does this get me?
With those few lines of code, your models are now reproducible. You can go back to any version of your model, from any time and re-create it. You can see changes you made, collaborate with friends, and share your models.
View the different iterations that your model went through.
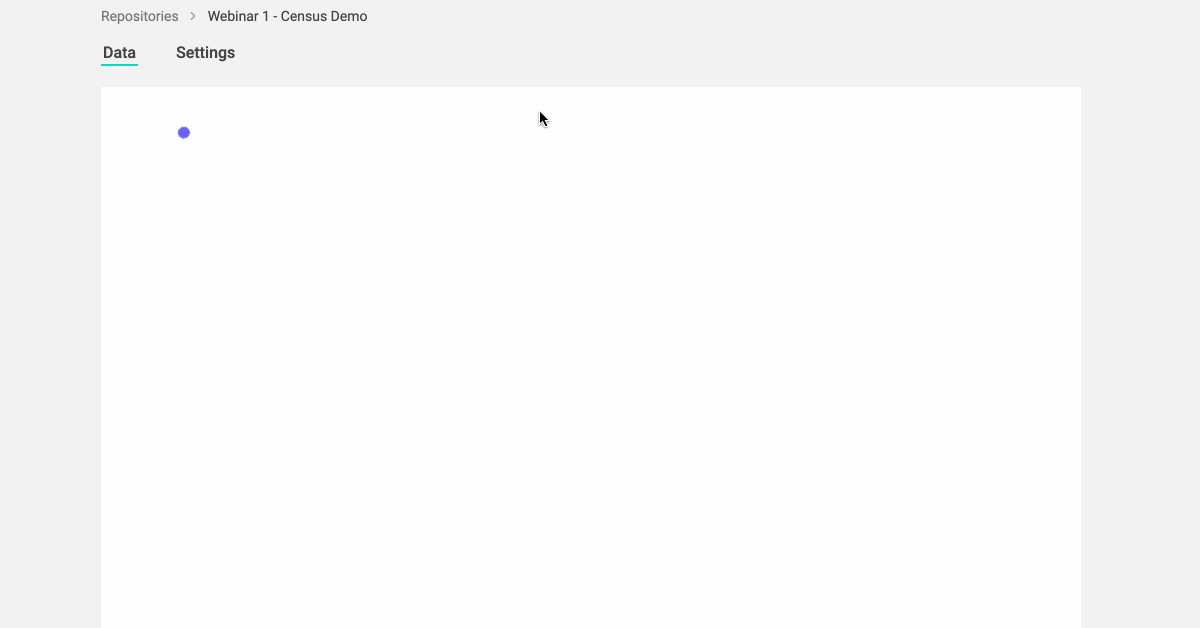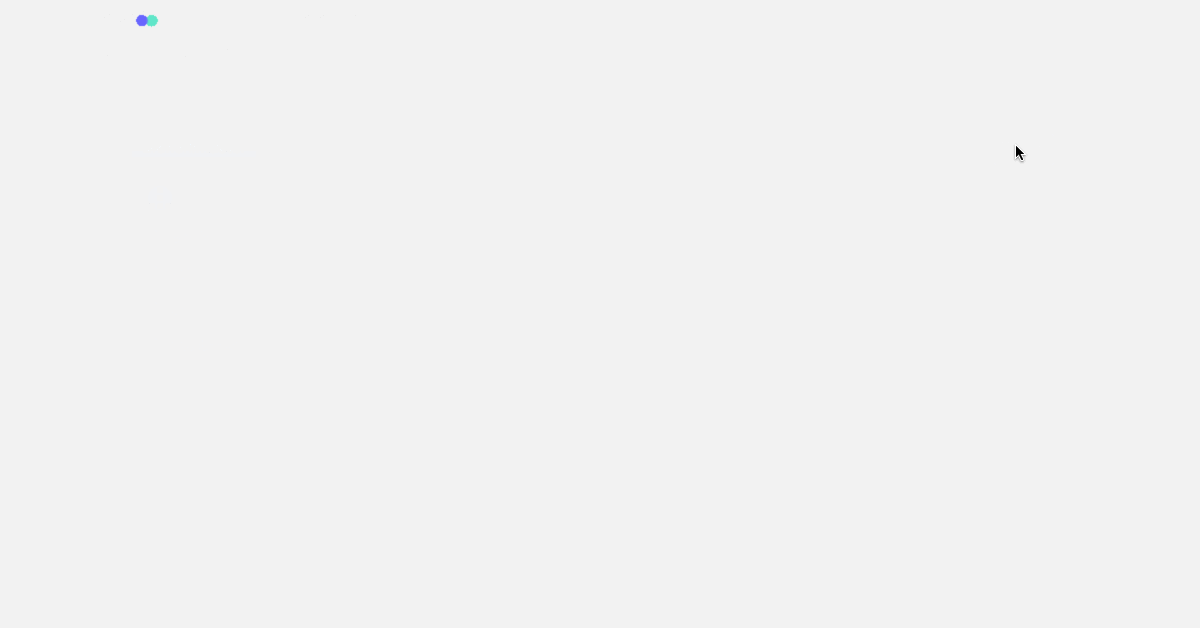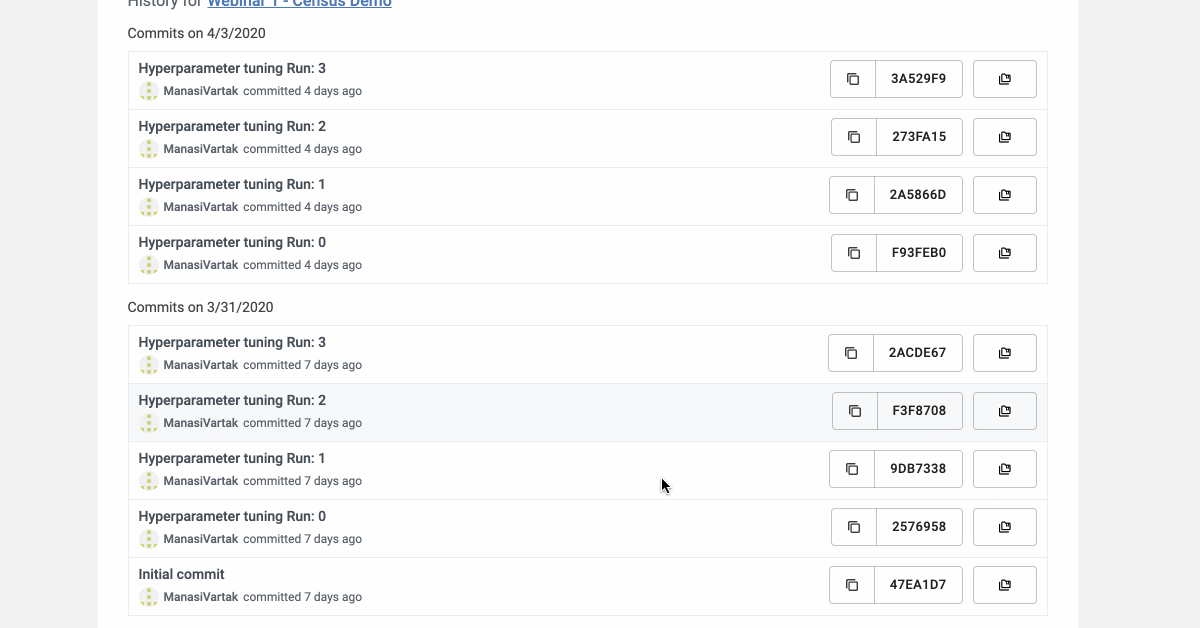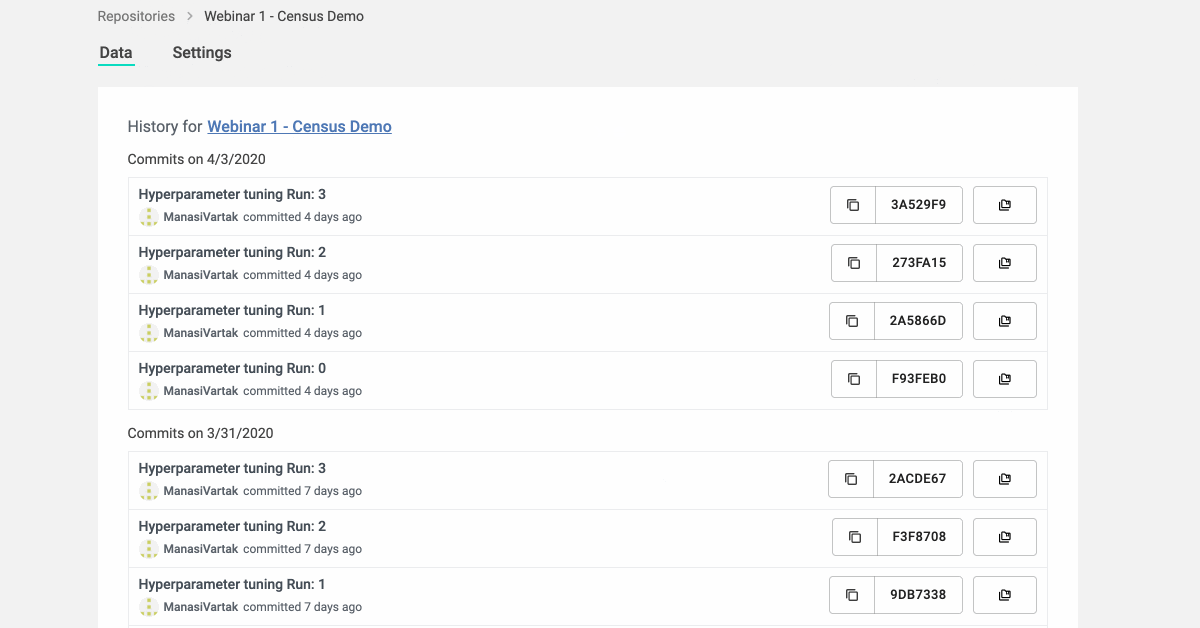
See the changes made to your model ingredients spanning code, data, config, environment.

Manage your work in a Git-like flow including branches, merges, and reverts.
Finally, share your work with colleagues and have them be able to fully reproduce the model!
Intrigued?
This was a quick peek into the functionality provided by ModelDB 2.0 and how it can be used to make models (or analyses) reproducible. Want to find out more?
- Check out the ModelDB project on GitHub — star it, fork it, and use it!
- Share your feedback at modeldb@verta.ai or on our Slack channel below.
- Join our model versioning community on Slack here.
About Manasi:
Manasi Vartak is the founder and CEO of Verta, an MIT spinoff MLOps software for the entire model lifecycle. Verta grew out of Manasi’s Ph.D. work at MIT on ModelDB, the first open-source model management system widely used in research labs and Fortune 500 companies. Previously, Manasi worked on deep learning for content recommendation at Twitter and dynamic ad-targeting at Google. Manasi has spoken at several top research as well as industrial conferences such as the O’Reilly AI Conference, SIGMOD, VLDB, Spark + AI Summit, and AnacondaCON, and has authored a course on model management.
About Verta:
Verta builds open-core MLOps software for the full model lifecycle. This includes model versioning, model deployment release, to model monitoring, all tied together with enterprise governance features. We are a spin-out of MIT CSAIL where we built ModelDB, one of the first open-source model management systems.
Subscribe To Our Blog
Get the latest from Verta delivered directly to you email.


