Since we wrote ModelDB 1.0, a pioneering model versioning system, we have learned a lot and adapting it to the evolving ecosystem became a challenge. Hence we decided to rebuild from the ground up to support a model versioning system tailored to make ML development and deployment reliable, safe, and reproducible.
We are excited to announce that ModelDB 2.0 is now available! We would like to thank all of our partners who inspired and helped design, test, and validate this release.
Before jumping into the details of this major release, let's have a quick look of what's new in ModelDB 2.0:
- Layered API-focused client, which allows easy extension of functionality and integration with frameworks
- Integration with popular ML frameworks like pytorch, scikit-learn, tensorflow and many others
- Artifact management to reliably track the result of the training process
- Git-based versioning for all components for a model
- Single pane of glass for a company’s model development
- User management support for authentication, RBAC authorization and workspace isolation
Model versioning
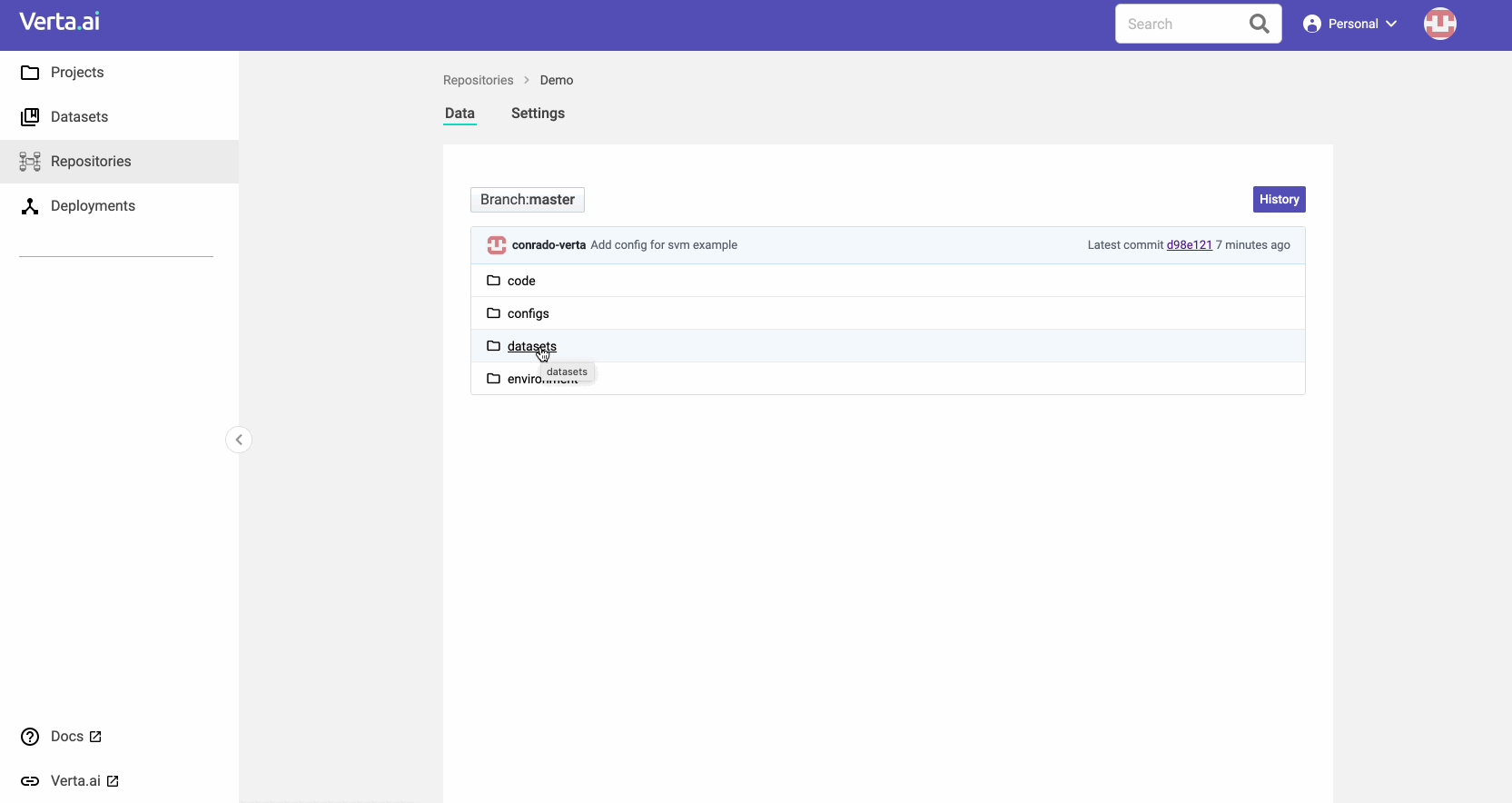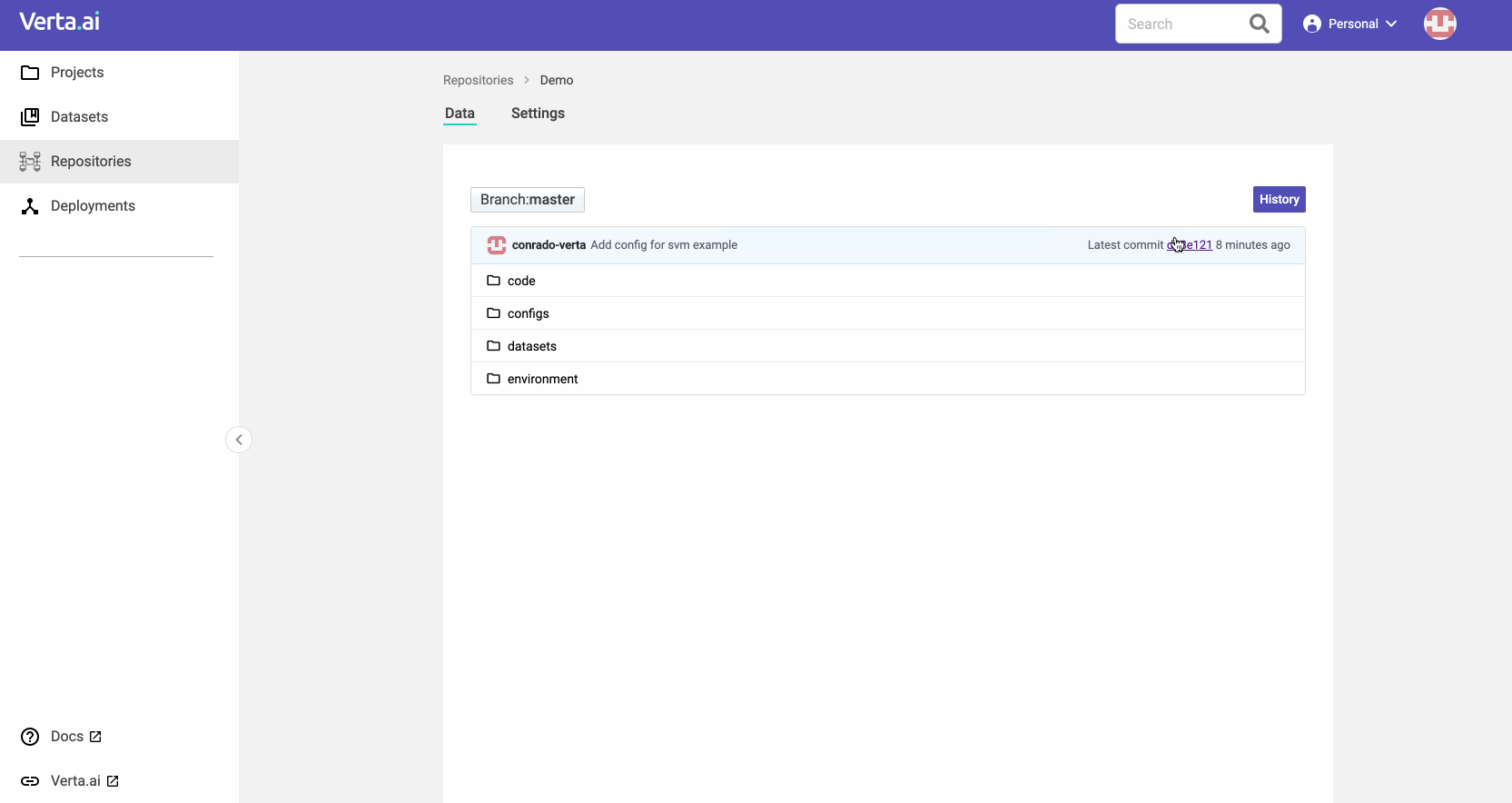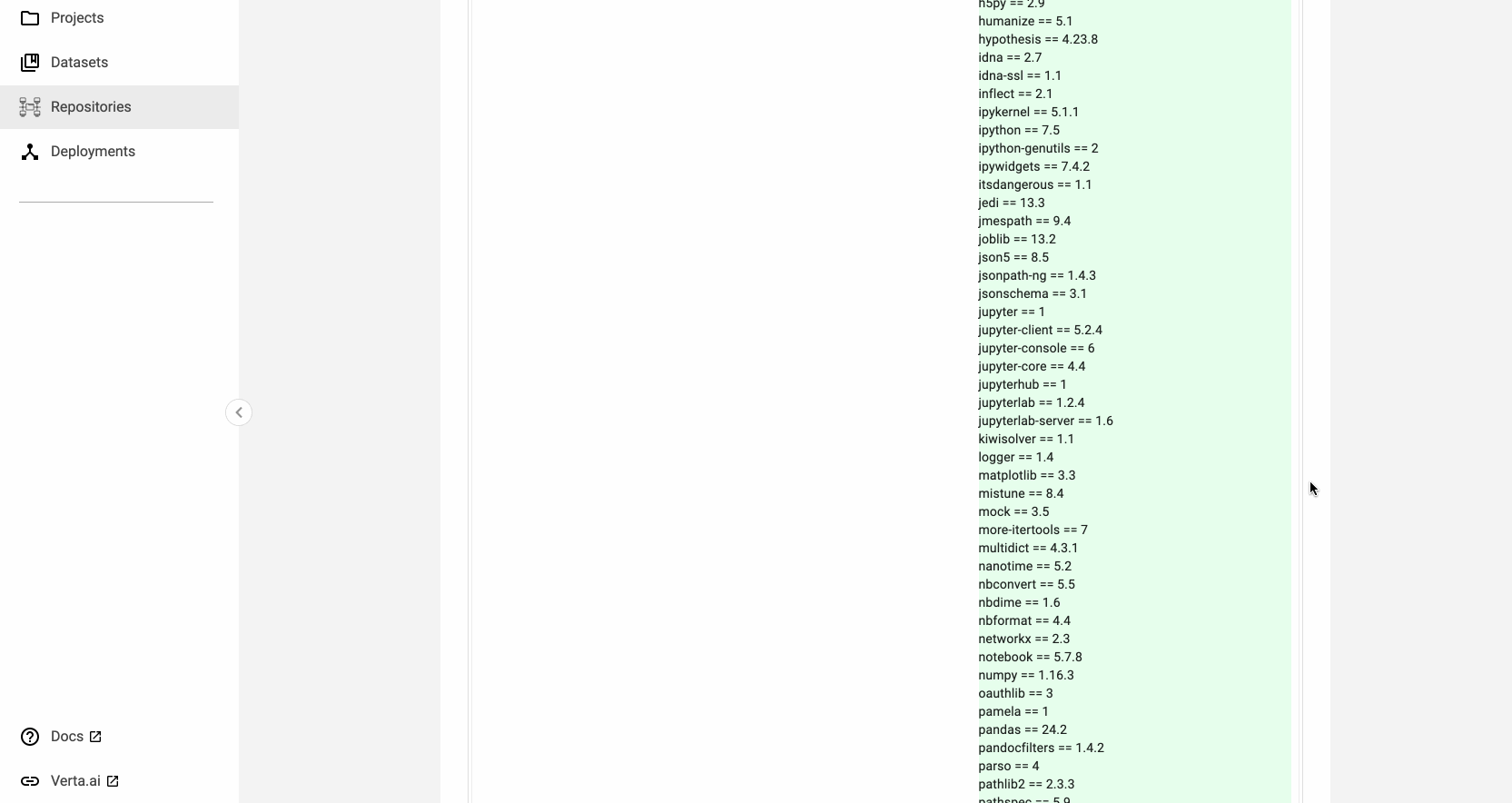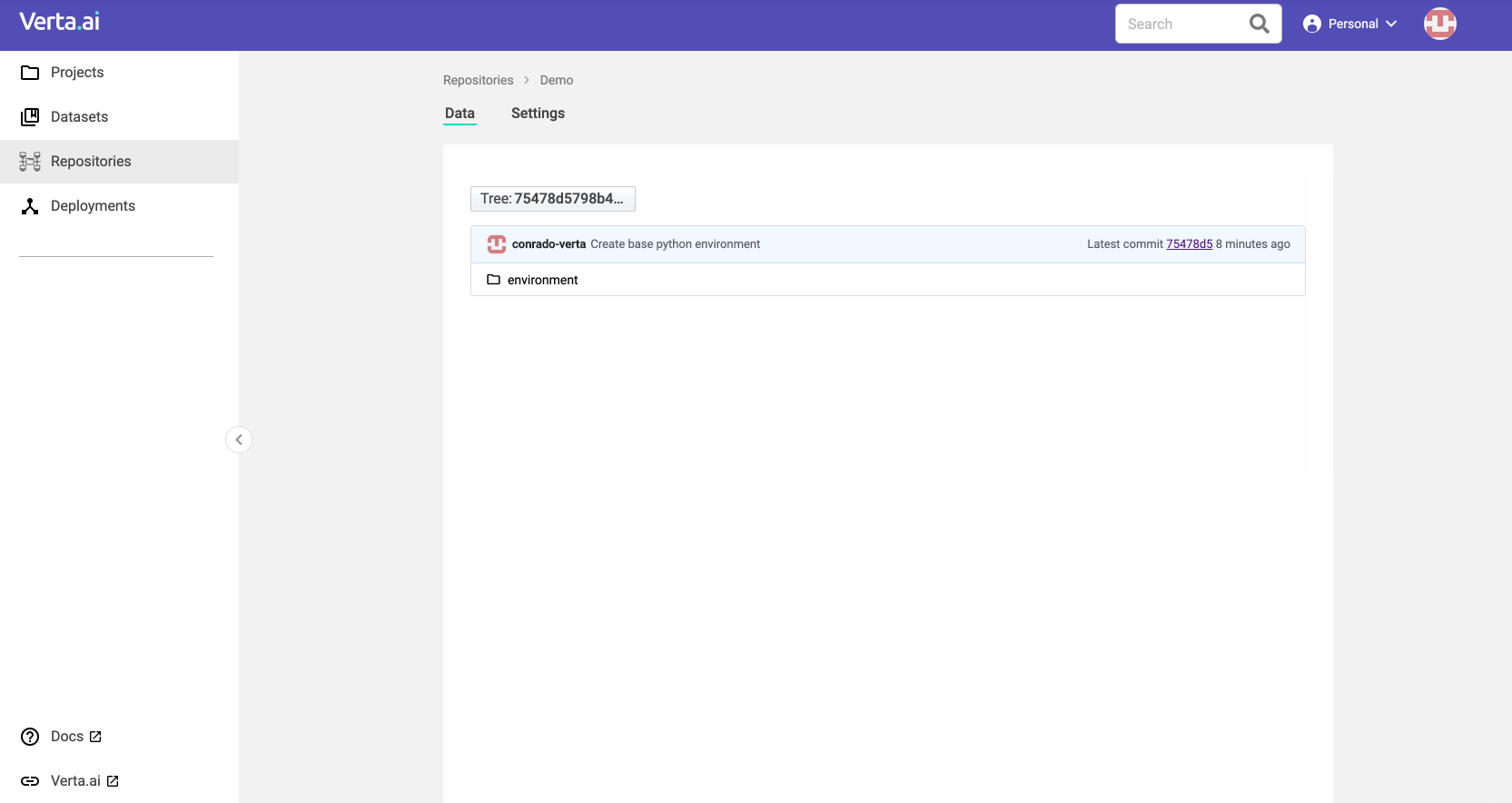
Back when we first created ModelDB 1.0, we only tracked metadata about models. However, having partnered with many organizations (in regulated industries and others) to operationalize their models, we learned that this isn’t enough. While extensive, metadata, does not enable you to go forward or backward in time to a specific state of a model. For instance, with metadata alone, you cannot go back to the exact state when a model was created three months back. So we built a new model versioning solution inspired by Git to manage all the ingredients to create a model: dataset, code, environment, and config.
.png?width=521&name=model%20versioning%20(1).png)
With the new versioning, you can:
- Version all components of a model in their multiple forms, like python or docker environments, S3 datasets, notebook code, and hyperparameter sets. Machine learning is diverse, and there is no single tool to solve all problems. You can also easily extend the existing types to support your needs using standard enterprise tools (java and a database).
- Integrate different versioning solutions, such as Git, databases, object stores, container repositories, and many other isolated sources. Use the right tool to manage each of your model ingredients, and we’ll help you track changes across all of them. We also provide a versioning system for those that don’t have it natively.
- Use like Git or like an API, which allows integration with anything between GitOps and notebook ecosystems. You can use our clients to manipulate the objects you care about and not worry about the constraints of disk-based systems. But you can also sync between ModelDB and your local Git.
- Commit, revert, branch, diff, and merge any changes to the repository like you would do for Git. Specialized tools to operate on the ingredients of the model make the experience smoother by embedding application knowledge instead of just assuming everything is text. Get all the benefits from GitOps without having to operate Git directly for the authentic MLOps experience!
Secure experiment management
ModelDB 1.0 was able to store model information, but did not support authentication and authorization. These are essential feature-sets to ensure that your data stays secured, especially for enterprises. So in ModelDB 2.0 we are now finally adding the necessary interfaces so that you can know exactly who did what and when, ensuring only authorized users have access. This will now also enable users to isolate sets of experiments for different teams.
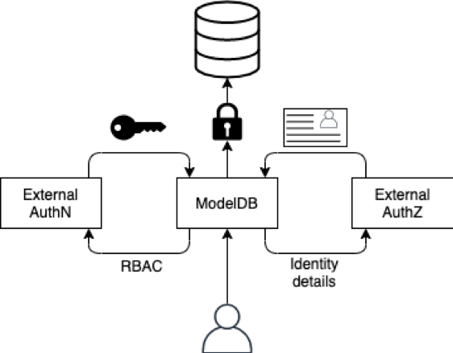
The new version enables you to:
- Control access with RBAC to experiments, defining who can perform operations. The APIs are publicly available and anyone can implement them for their use cases. ModelDB will manage the creation of roles based on the resources it knows about, and check for permission on every user action. You can also leverage our enterprise offering, which provides a fully integrated solution! We have user management with teams and organizations, besides integrating with different authentication systems,
- Use workspaces to separate, providing total isolation between environments. You can use it to separate your development and production models, or even separate between teams.
- Identify who are the authors of models, versioning changes, and any other component. Know who in the team can assist with an issue, or who is the best person to contact about a model. Always be on top of the people in the organization.
We’ll also be sharing the design principles behind our RBAC system, which provides a solution learned from analyzing the best in class. Sign up for our newsletter to get notified when they come out!
Centralized dashboard
One of the features from ModelDB that our users most enjoyed was the web experience It allowed them to get a full view of the experiments they had done. In this new version, we double down on building a fantastic user experience via our UI to help our users navigate even easier through their models.
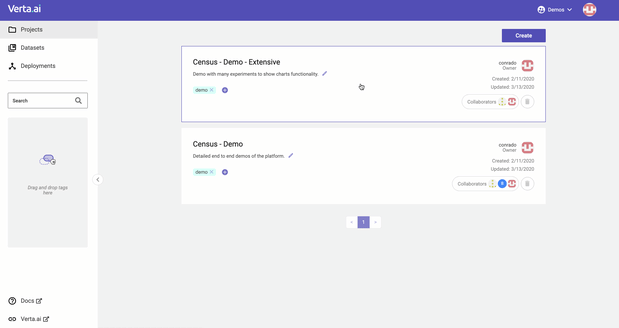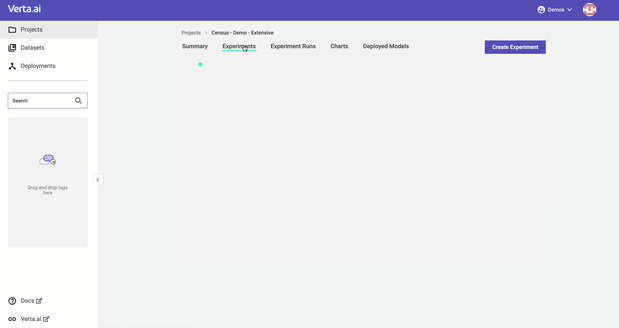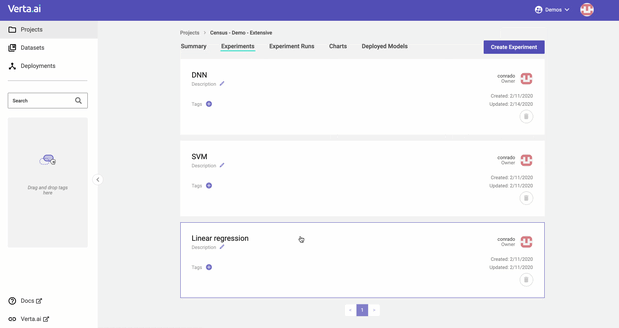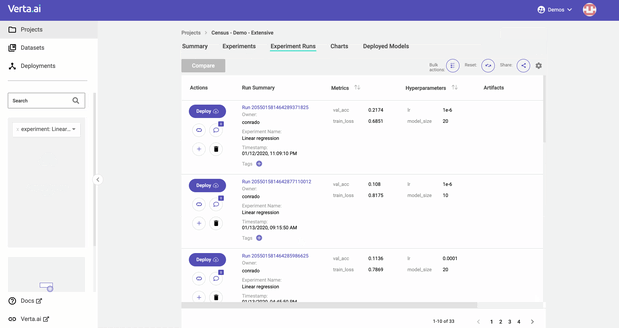
With ModelDB 2.0, you can:
- Organize your work, using projects, experiments, runs, tags, descriptions, and anything else you need to navigate multiple development fronts and never lose anything.
- Search and filter across models to find the ones you need. We can filter on any characteristic of the run, including metrics and hyperparameters. You can use either our UI or our clients to iterate over the models that you find.
- Manage inputs and outputs of the modeling process, saving inputs in our versioning. We have specialized output types for metrics, observations, and some types of artifacts. You can also save any binary as an artifact, and we’ll manage the storage for you in an object or file storage system.
- Analyze charts containing all your models to understand what is working. We provide state of the art analysis tools to help you and your team understand where to put efforts best.
- Compare different versions of models to understand what has changed and how it impacts the quality. Just store all information that you want while developing and understand the evolution of your project over many iterations.
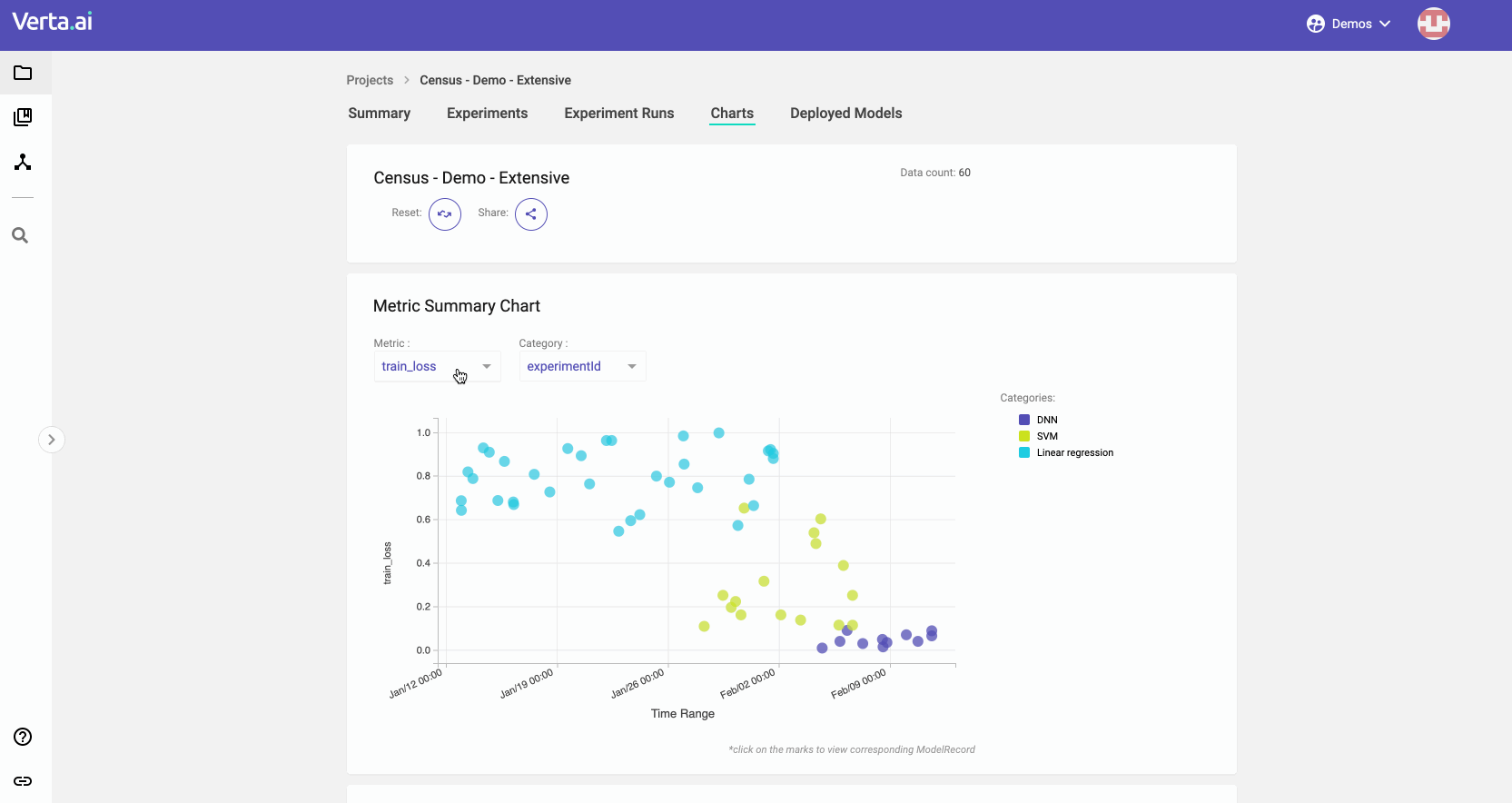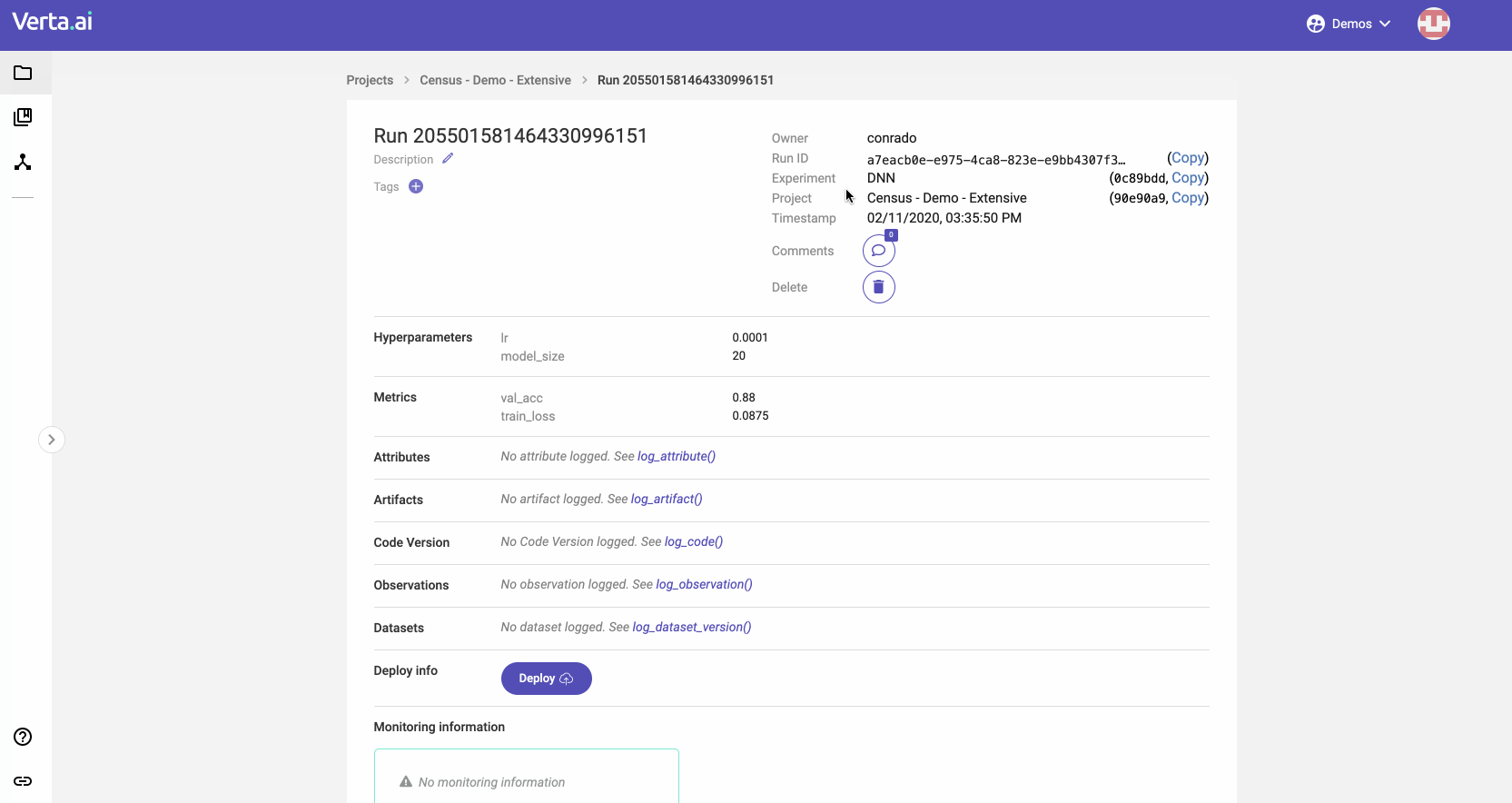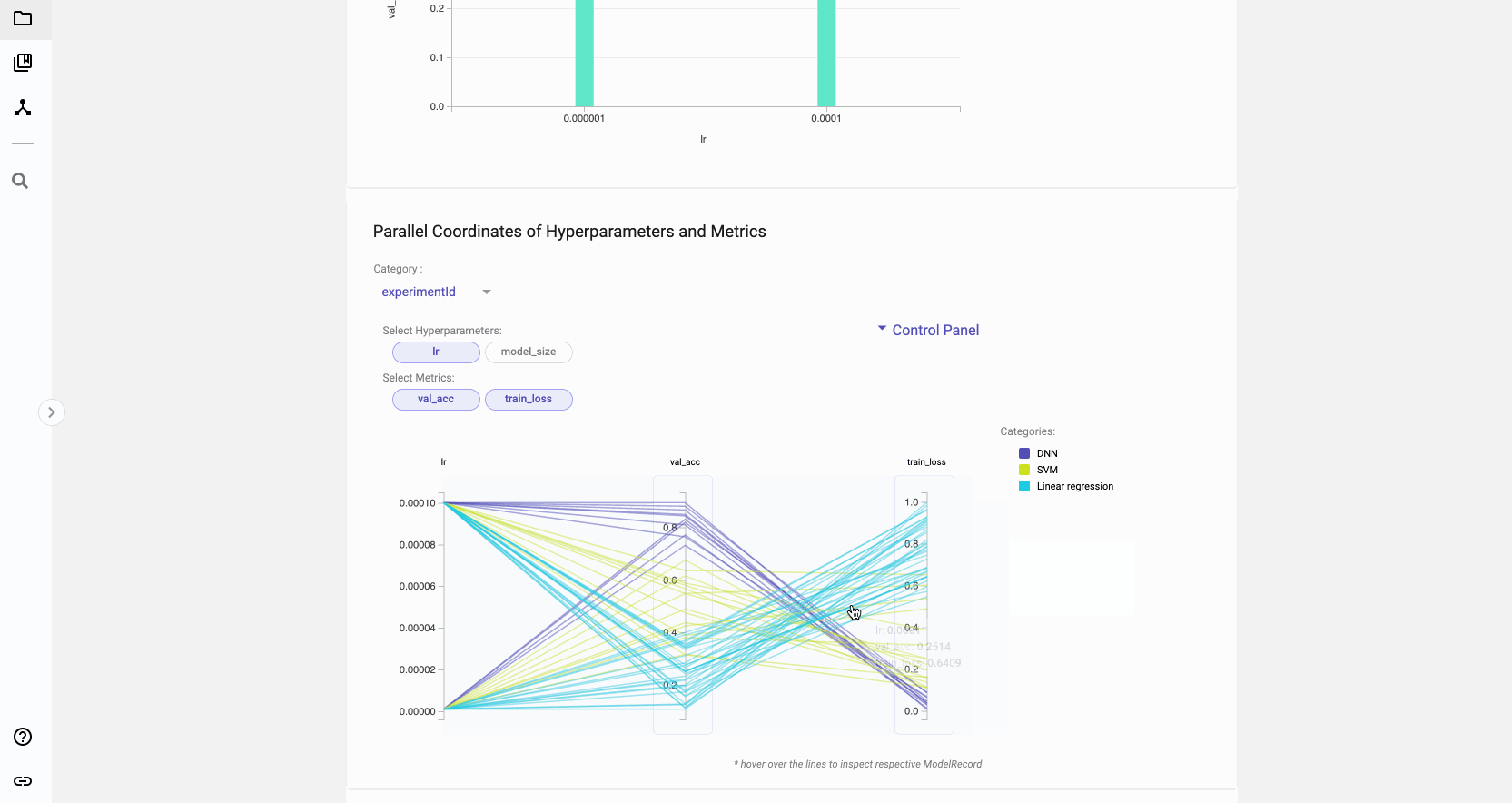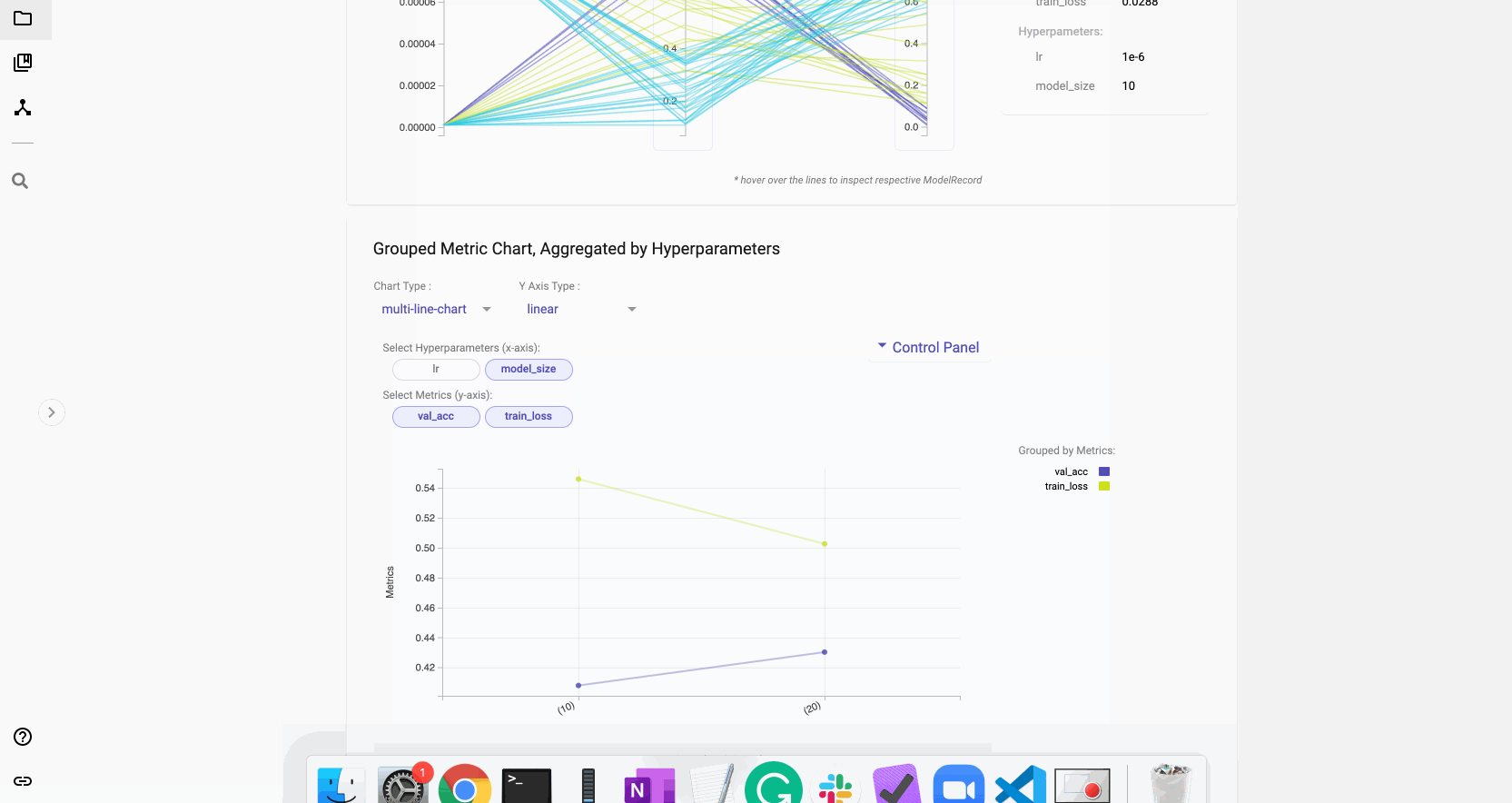
If you’re curious to better leverage all the modeling you and your team do, sign up for our upcoming webcast. We’ll show you how to increase your modeling speed by allowing you to focus on modeling!
Get started today
We make ModelDB 2.0 available in a wide range of formats:
- Docker containers
- Helm templates
- AMIs
- you name it :)
We want to make sure everyone can take their first step towards agile and robust modeling! Check out our Git repository or sign up for our SaaS offering. We’d love to hear your feedback, so join us on Slack and let’s discuss how to continue improving ML versioning.
PS: we are hiring. Let us know if this space excites you!
About Verta:
Verta builds software for the full ML model lifecycle starting with model versioning, to model deployment and monitoring, all tied together with collaboration capabilities so your AI & ML teams can move fast without breaking things. We are a spin-out of MIT CSAIL where we built ModelDB, one of the first open-source model management systems.
Subscribe To Our Blog
Get the latest from Verta delivered directly to you email.


