
This blog post rounds off of our blog series on Serverless Inference for Machine Learning models accompanying our KubeCon 2020 talk: Serverless for ML Inference on Kubernetes: Panacea or Folly? - Manasi Vartak, Verta Inc. We'll be hosting a live replay on December 2nd at 2 PM ET for anyone who missed it.
As builders of the Verta MLOps platform, we often get asked whether serverless is the right compute architecture to deploy models. The cost savings touted by serverless seem extremely appealing for ML workloads as for other traditional workloads. However, the special requirements of ML models as related to hardware and resources can cause impediments to using serverless architectures.
To provide the best solution to our customers, we ran extensive benchmarking to compare serverless to traditional computing for inference workloads. In particular, we evaluated inference workloads on different systems including AWS Lambda, Google Cloud Run, and Verta.
In this series of posts, we cover how to deploy ML models on each of the above platforms and summarize our results in our benchmarking blog post.
- How to deploy ML models on AWS Lambda
- How to deploy ML models on Google Cloud Run
- How to deploy ML models on Verta
- Serverless for ML Inference: a benchmark study (this post!)
This post summarizes the results from our benchmarking study.
What is serverless and why is it interesting?
Serverless is, at its most simple, an outsourcing solution.
-- Martin Fowler, https://martinfowler.com/articles/serverless.html
Today, there are a variety of ways in which one can run ML applications, all the way from provisioning bare metal servers to running an application on a VM that abstracts away the details of the hardware to using containers on Kubernetes, that abstract away the OS, and finally to serverless that abstracts away all but the details of the application logic.
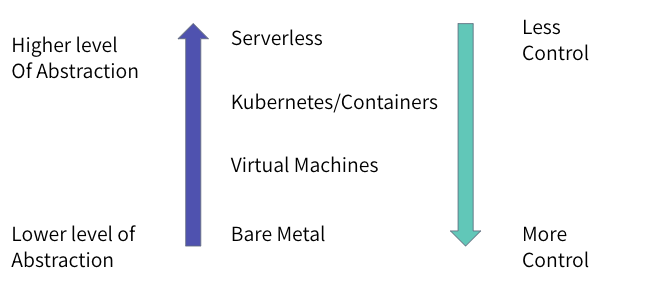
In particular, a serverless architecture (in particular, a function-as-a-service) abstracts away all the details of provisioning and managing servers and does not involve a long-running server component (e.g., a server waiting to process requests). A developer must only run code for the business logic without having to figure out how to deploy or run it. The serverless platform takes care of deploying and scaling the application -- scaling up and down of resources as workload changes and can scale to zero when there is no load. Popular serverless platforms include AWS Lambda, Google Cloud Functions, GCP Cloud Run, and AWS Fargate.
Advantages of serverless architecture
Since serverless architectures abstract away everything but the business logic, serverless makes application development and deployment extremely easy. Specifically, serverless is:
- Simple to use (developers can focus on business logic)
- Simple to scale (more copies of the serverless instance created automatically)
- Low infrastructure maintenance overhead (don’t need to manage nodes, perform upgrades, tune resources requirements)
- Potentially cost-effective depending on workload (don’t need to provision resources that will not be used)
Limitations of serverless architecture
- Serverless applications are stateless
- Implementation restrictions: limits on execution duration, resources available (e.g., memory, CPU, disk, concurrency)
- Cannot choose/control hardware
- Large latency on cold-start
As a result, serverless architectures typically make sense when an application meets a few criteria:
- the application should be able to made stateless;
- the application latency and associated SLAs are not stringent;
- and workloads handled by the application are highly variable.
As we will see in the benchmarking section below, a limitation imposed by current implementations has to do with the resources available in serverless implementations today.
One argument made in favor of serverless architecture is that they are cheaper than a traditional compute architecture. However, depending on the workload, e.g., a consistent query workload, a traditional compute architecture, where servers are constantly provisioned, may be cheaper. Where serverless does shine is low TCO (total cost of ownership) that includes not just the infrastructure but also the human resources cost of having headcount to manage infrastructure (upgrades, patches, provisioning etc.) See these for more info: 1, 2, 3.
Unique considerations for ML Serving
So those are the typical considerations for serverless architecture, what about serving workloads (i.e., making predictions using a trained model)? Let’s start by considering what’s unique about ML models:
ML models can be large in size
Deep Learning models are famous for having millions, if not billions of parameters. For example, the BERT model has 110 million params, GPT-2 model from OpenAI has 1.5 billion params. As a result, the size of deep learning models in the hundreds of MBs if not a couple of GBs. Case in point, the DistilBERT model is 256MB.
Compare these to a typical lambda (few hundred bytes) that might be responsible for making a database request whenever an incoming event is fired. This large size of models makes it extremely challenging to use current serverless architectures for serving ML models (more below).
ML libraries can be large and varied
Next, ML models are typically used alongside ML framework libraries like PyTorch, Tensorflow, HuggingFace, Fast.ai etc. Like the models they support, these libraries also have sizes in the many hundreds of MBs, hitting resource limitations. In addition, these libraries have specialized optimizations that may be applied depending on the hardware they are running on. As a result, in order to run these libraries in the most efficient manner, having control over the hardware running the models is crucial (e.g., --config=mkl for Tensorflow).
ML models may require specialized hardware
Finally, related to the above considerations, ML models often include operations (e.g., matrix multiply, other linear algebra operations) that can take advantage of hardware accelerators like GPUs and TPUs. Consequently, having the ability to select specialized hardware during inference can be key.
Benchmark
As providers of the Verta MLOps Platform, we often get asked by customers about using serverless architectures for ML serving given the interest around serverless and the potential cost savings. Since the tradeoff is unclear at the surface, we ran a benchmarking study assessing whether serverless architectures are a good fit for serving different ML models.
To evaluate serverless architectures, we picked 3 systems:
- Arguably the state-of-the-art in serverless, AWS Lambda
- An innovative serverless offering on Kubernetes, Google Cloud Run
- A traditional computing architecture using containers on Kubernetes, Verta MLOps Platform.
We chose these platforms because they represent the get implementation choices in serverless: (1) run functions vs. containers, (2) run containers on serverless, (3) do not run serverless.
To learn more about how to serve ML models on each of these platforms, check out these blog posts on serving models in AWS Lambda, Google Cloud Run, and on Verta.
For each of the above systems, we ran workloads serving different ML models and with varying queries per second (QPS). Each experiment evaluated the systems for usability concerns (can the system actually serve the model), prediction latency (warm-start), time-to-first-prediction (cold-start latency), and time-to-scale in response to varying workloads.
Before we get to the results, a few caveats!
The offerings and landscape for serverless platforms, particularly for Kubernetes, is still evolving. As a result, the benchmark results presented below are based on the software and capabilities available as of October 2020. For managed services, there are knobs that cannot be controlled by the end-user (e.g., chipset used in the nodes) and similarly optimizations that are not exposed to the end-user. Therefore, a complete apples-to-apples comparison of the platforms is challenging. To perform a fair comparison, we use off-the-shelf settings available on the platform.
Results
1. Usability Concerns
As mentioned above, serverless platforms have hard restrictions on resources that a serverless application can use. This translates to limits on memory, CPU, disk, number of concurrent requests etc. In addition, specialized hardware cannot be provisioned for use in a serverless setting. The relevant limitations are shown below:

These limits have a very real impact on serving models in these systems. For example, as discussed in our How to deploy ML models on AWS Lambda blog post, deploying DistilBERT requires disk space significantly larger than what is available. As a result, one must perform a lot of optimizations (read: hacks) to make the model and libraries fit into a Lambda. Specifically, the model must be downloaded from S3 at run-time and loaded into memory and second, the developer must figure out what parts of the ML library (in this case HuggingFace) can be deleted from the package in order to make the library fit into the disk size limitations.
These resource constraints come up for almost every deep learning model one may want to deploy. In an extreme case, a customer wanted to serve a model that consisted of an embedding model followed by a nearest neighbor model. Together these models required >20GB in memory/disk space. These types of resources are currently impossible to obtain in a serverless platform; making it impossible to serve this model using any of these platforms.
Finally, note that ML libraries have optimizations that are hardware-specific, however, since serverless platforms do not allow hardware to be selected, these optimizations cannot be applied.
2. Warm-start prediction latency
Ok. Now suppose that your model fits within the resource constraints imposed by the serverless platform. Then we can look at the time required on each platform in a warm-start setting; i.e., when the serverless application has already been initialized.
The results for warm-start (p50, P95, P99) are shown below for the DistilBERT model:
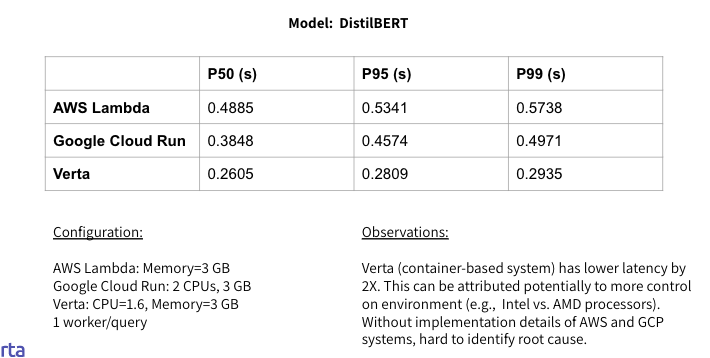
We see that the latency for AWS Lambda and Google Cloud Run are comparable, while the Verta latency is 2X lower. Since the model code running in all three systems is the same, the difference can be attributed to more control over the environment (e.g., type of processors used), potentially the serving code, and optimizations happening behind the scenes (e.g., batching).
3. Cold-start prediction latency
Next, we look at cold-start prediction latency numbers. In this setting, we measure the time to service the first request made to the serverless platform, i.e., the latency when the serverless application has not been initialized with the relevant state.

As we see above, the numbers look very different for the serverless platforms and Verta. Lambda takes a whopping 41s to serve the first request, which is actually larger than the limit of 30s for its API gateway. Due to the lack of visibility into AWS Lambda, it is hard to determine where exactly this time is being spent but the optimizations we had to perform to get the library to fit into AWS Lambda are likely one of the factors here. In contrast, in a non-serverless platform like Verta, there is always a model ready to go. As a result, the latency is 10X lower than the serverless platforms and the cold-start numbers are much closer to the warm-start ones.
4. Scaling latency
Next, we assess how the different systems respond to varying load on the system. For this experiment, we increased the query throughput from 1 QPS to 100 QPS and measured the time to reach steady state (i.e., time to successfully service 100 QPS).

Here we see the opposite trend than before. The non-serverless system is at least 3X slower than the serverless systems. Both the serverless systems are optimized for instantaneous scaling and can take advantage of the fluidity of resources arising from many thousands of serverless functions running simultaneously. On the non-serverless system, scaling only the pods running on Kubernetes is much faster than also scaling the number of nodes. Non-serverless systems can be optimized to match the performance of serverless systems by applying optimizations such as always having hot-replicas ready to go and over-provisioning resources. Note that both of these have negative cost considerations.
5. Varying Model Size
We see the trends from above across the board for different types of deep learning models. The trends are less visible for small models like linear regressions. In the table below, we show how the key metrics change with increase in model size for deep learning models.
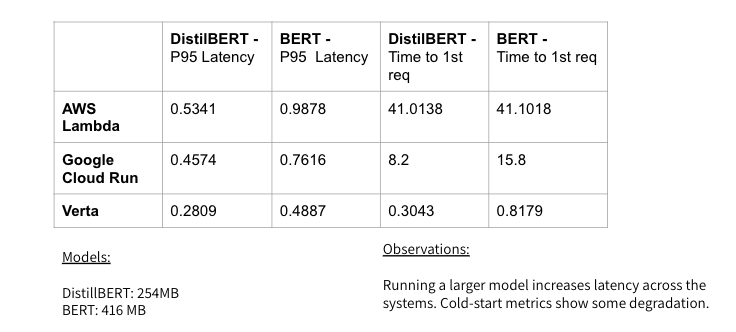
DistilBERT is roughly half the size of BERT and we see this size difference reflected in the inference latency for these models. For instance, the warm-start latency for BERT is roughly 2X that of DistilBERT.
Interestingly, we find that the time to first request doesn’t have as clear of a pattern; for both the container-based systems, cold-start latency is 2X for BERT compared to DistilBERT. For AWS Lambda, we do not see a significant difference in the time to first request.
6. Cost
Finally, we come to the one of the key considerations for serverless -- cost of running an application. And this is one where the tradeoff heavily depends on the exact workload run on the system and therefore there is no one single answer. The cost of serving a model on serverless when the workload is spiky would be cheaper than serving the same model on a non-serverless system with over-provisioned resources (to match the workload demands).
As mentioned before, where serverless systems do often shine is the TCO (total cost of ownership) that includes the human resource costs associated with developing software infrastructure, maintaining it, and also operational costs (see: 1, 2, 3).
Key takeaways
So those are the key results from our benchmarking study. For the full results, check out this spreadsheet.
If you wondering if serverless is appropriate to serve your ML models, here’s a handy guide:
- Current serverless platforms have hard limits on resources available. If your model does not fit into these constraints, it will either be impossible to run the model in a serverless fashion or will require a bunch of code surgery (see this blog post). Note this is very likely to be the case with deep learning models.
- If low cold-start latency is important to your application, serverless systems will not be a good fit
- Where choice of hardware greatly impacts your model performance and the goal is to optimize for latency, serverless again is not a good choice
- Serverless systems shine when the workload is bursty and time to scale is important
- The infrastructure cost of running your inference service in a serverless fashion depends closely on the workload; in addition, it’s worth accounting for the non-infrastructure costs associated with a serving application.
So that’s it! Making the choice of using a serverless architecture is nuanced and depends closely on the workload. As serverless offerings add more flexibility in terms of resource constraints and mitigating cold-start latency, they may become more appealing for ML serving applications.
Where do we go from here?
We recognize that there are a number of systems out there that can serve models, both in a serverless architecture and a traditional architecture. In addition, there are a number of other models to study. Let us know what you’d like to see (and if you are open to contributing!) and we’ll add that in for 2021!
Did we get you intrigued about Verta?
Learn more about our platform here and instantly sign up for trial here.
Subscribe To Our Blog
Get the latest from Verta delivered directly to you email.


