Using machine learning models in products is hard. Most companies fail at extracting value from them because they can't operationalize models properly.
We have gotten good at creating models and iterating on them, but most companies still don't use them well. A model with acceptable performance that you can use is better than a great model that you can't. Then why are companies having so many issues leveraging them?
In this blog post, we show that some challenges are analogous to those before DevOps. We’ll also show that others introduce a new level in the development and operation process that requires a new stack.
The lessons here come from building ML products and platforms at companies like Twitter, NVIDIA, Cloudera, Google, and others. These companies have invested heavily in building their in-house ML platforms or external products for a variety of scenarios.
Moving development closer to operations
Two decades ago, software development was painful. Developers and operators were silos, and making any changes was an adventure. DevOps helped us fix that with a simple shift in mindset: developers should own their software end-to-end, and operators should support them. Operators could focus on building robust IT infrastructure instead of handling each application individually. Meanwhile, developers could speed their development practices by using the tools as their product demanded. This change was the first wave of operationalization, and it changed how we do software.
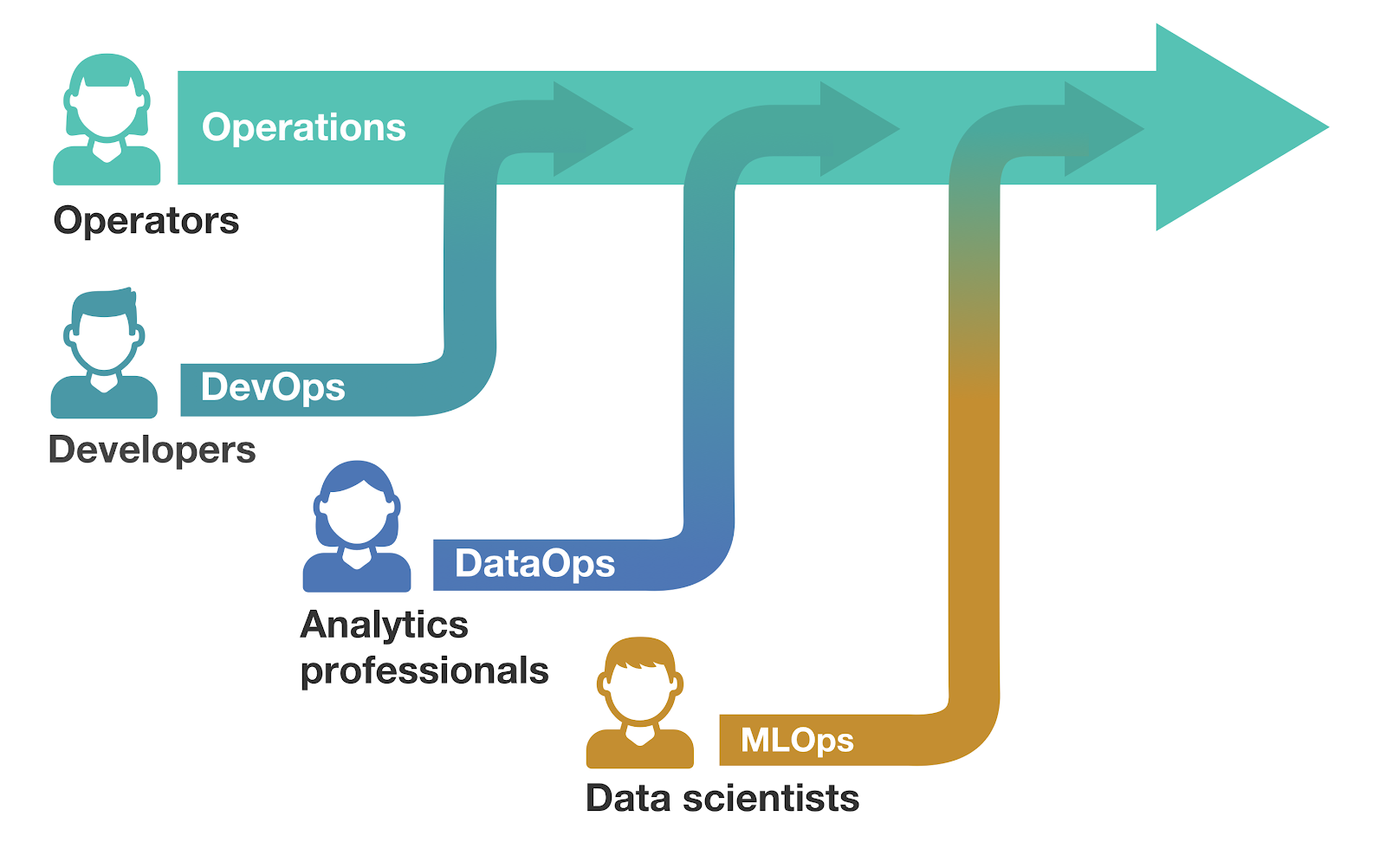
Around the same time, data started to become more relevant via analytics. The goal was to understand the data companies had available. Seeing the success of DevOps, analytics professionals partnered with their operators to create DataOps. In this case, analysts could focus on their business use case while operators made their use reliable.
Today, machine learning faces a similar challenge. The goal of ML is to help products make decisions on the spot. For example, which messages to show from a search query. These applications focus on actively improving the business instead of just providing insights. However, these more complex applications also have requirements we had never seen, and the operations world is just starting to adjust.
We now face a similar challenge for model developers that we have encountered before in software development:
- Data scientists don't own their work end-to-end. Instead, they send their models to a software developer and data engineer to build the machinery on a case by case basis.
- Data scientists are frequently blocked, waiting for other developers to help them.
- Data scientists are blind to the processes required to satisfy operations until it's too late. In which case, the work is dropped or re-done.
Why MLOps is so hard
Using ML models in products is a quantum leap in their value, and every such significant change comes with paradigm shifts. Not only MLOps is hard on itself, but most companies are not prepared to practice it today if done naively. The challenges of adopting MLOps boils down to:
- You have to support multiple pre-existing tools in two isolated ecosystems;
- Models have more dimensions in their requirements, and operate on a broader range of each trade-off;
- You need to provide a self-service ecosystem for data scientists that currently don't have the operations skills that developers do;
- Companies' processes on using ML must start where they're at today and adapt as their use advances;
- ML adds an entirely new layer to the operations stack.
MLOps challenge 1: pre-existing ecosystems
Software development and model development have pretty mature ecosystems today, with constant and fast improvements. However, these ecosystems are mostly isolated. Consider a core piece of infrastructure: the workflow system. Software engineers will most likely use Jenkins, GitLab, CircleCI, or any similar tools. However, data scientists use Airflow, Kubeflow, and other ML-targeted workflow systems. These two ecosystems might eventually combine, but this can take years and a lot of effort. Instead, we need to meet them where they are today.
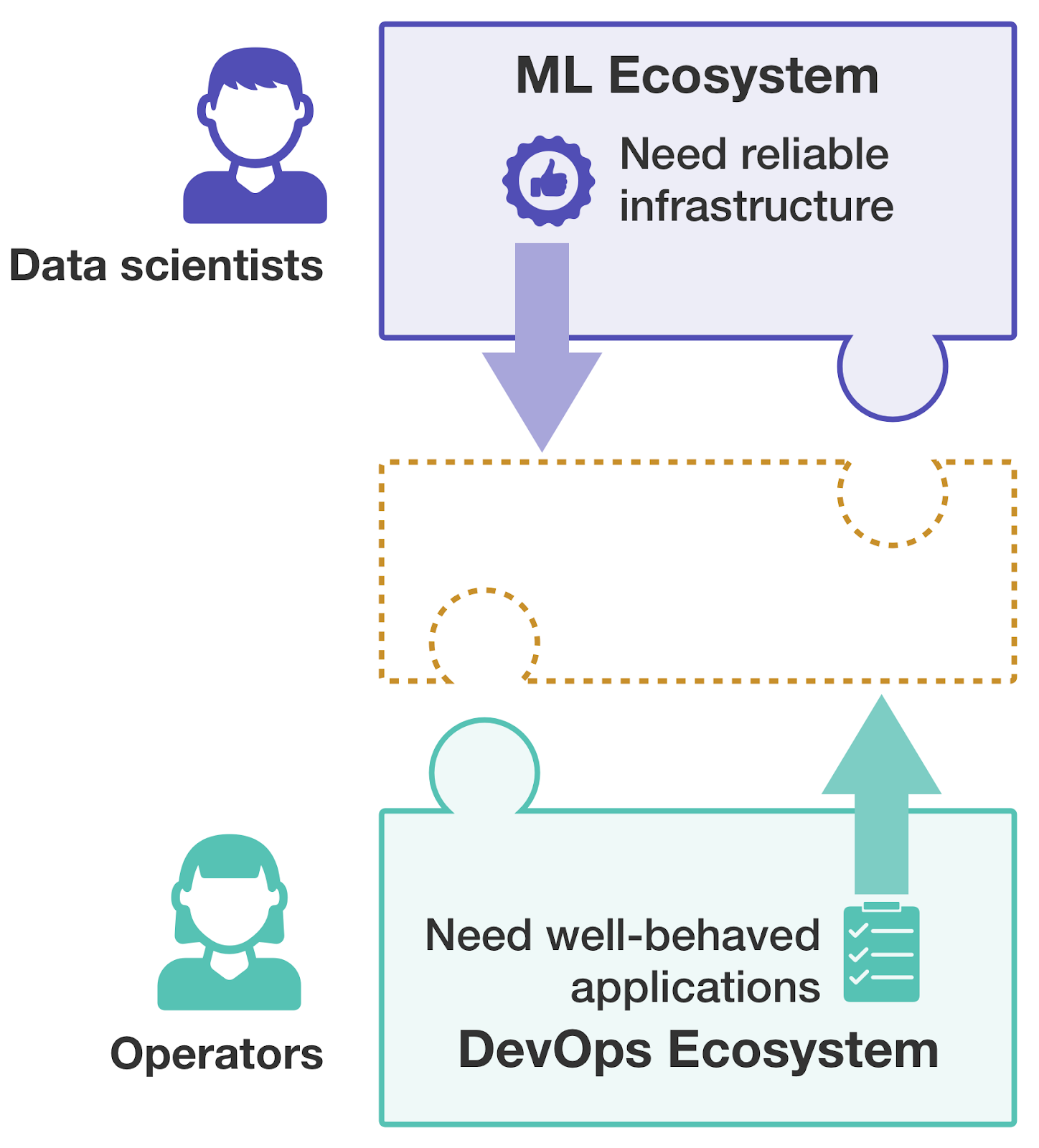
From the data scientist's perspective, they need the infrastructure to be reliable. It should work in the way that they want almost always and provide all the functionality they want to use but not develop. The researcher isn't concerned with which tools achieve this goal, as long as it works with their current solutions.
On the other hand, IT provides a vibrant ecosystem of productivity tools, but they require applications to behave in a particular way. The challenge operators face with data science today is that adapting all those practices to the ML ecosystem is difficult and time-consuming. So they need the ML applications to look like applications they already support.
This golden standard is hard to achieve. Therefore most companies end up with multi-year migration projects that change how everyone does their job simultaneously. As you can imagine, these projects fail most of the time. Instead, we need to figure out how to get these two personas to collaborate first and get value from each other.
MLOps challenge 2: dimensions of model requirements
In modern software development, the system's requirements are usually pretty narrow, so tools can be more focused. Models not only have more dimensions, but the placement of a solution is also fuzzier.
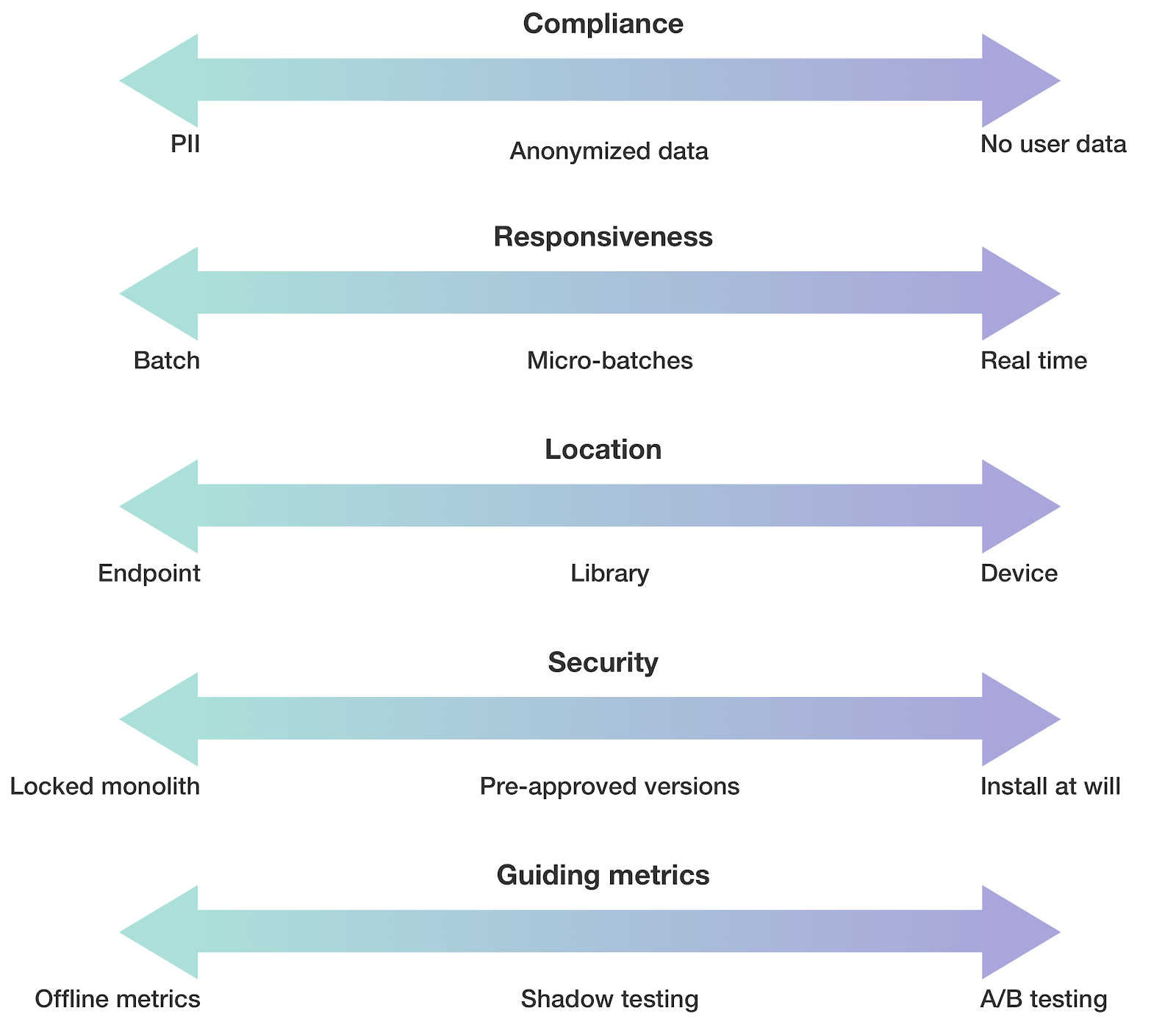
These are just a few examples of standard dimensions considered and it’s by no means an exhaustive list. Note how software usually lies on clear points in the spectrum. For instance, you know if the application provides an HTTP endpoint or runs in the user's device. Unsurprisingly, that is generally not the case for models. During the lifecycle of the model, from conception to use in a product, the same model might be at different places in the requirements balance. Using the same example, we might not use the end device for computing our test metrics due to speed concerns, but use the model as a library instead.
Most companies start to deploy models by building a solution for a particular case and ignoring others. Then they patch it a little bit to adapt to another model or another use case of the same model. And again, until they end up with a system that is hard to use, change, and maintain.
In which case, new users might consider it's easier to build their own from scratch for their use case. That's how many companies, including big tech ones, end up with multiple internal ML platforms if they're not careful. Keeping in mind the diversity of requirements, even within a single project, is an essential but challenging effort.
MLOps challenge 3: self-service operations for data scientists
One of the core tenets of DevOps is that developers should own their applications end-to-end. To do this properly, operators needed to provide mechanisms for their users to self-service. It allows IT to scale to multiple customers and removes delays waiting on someone else to provide some tooling.
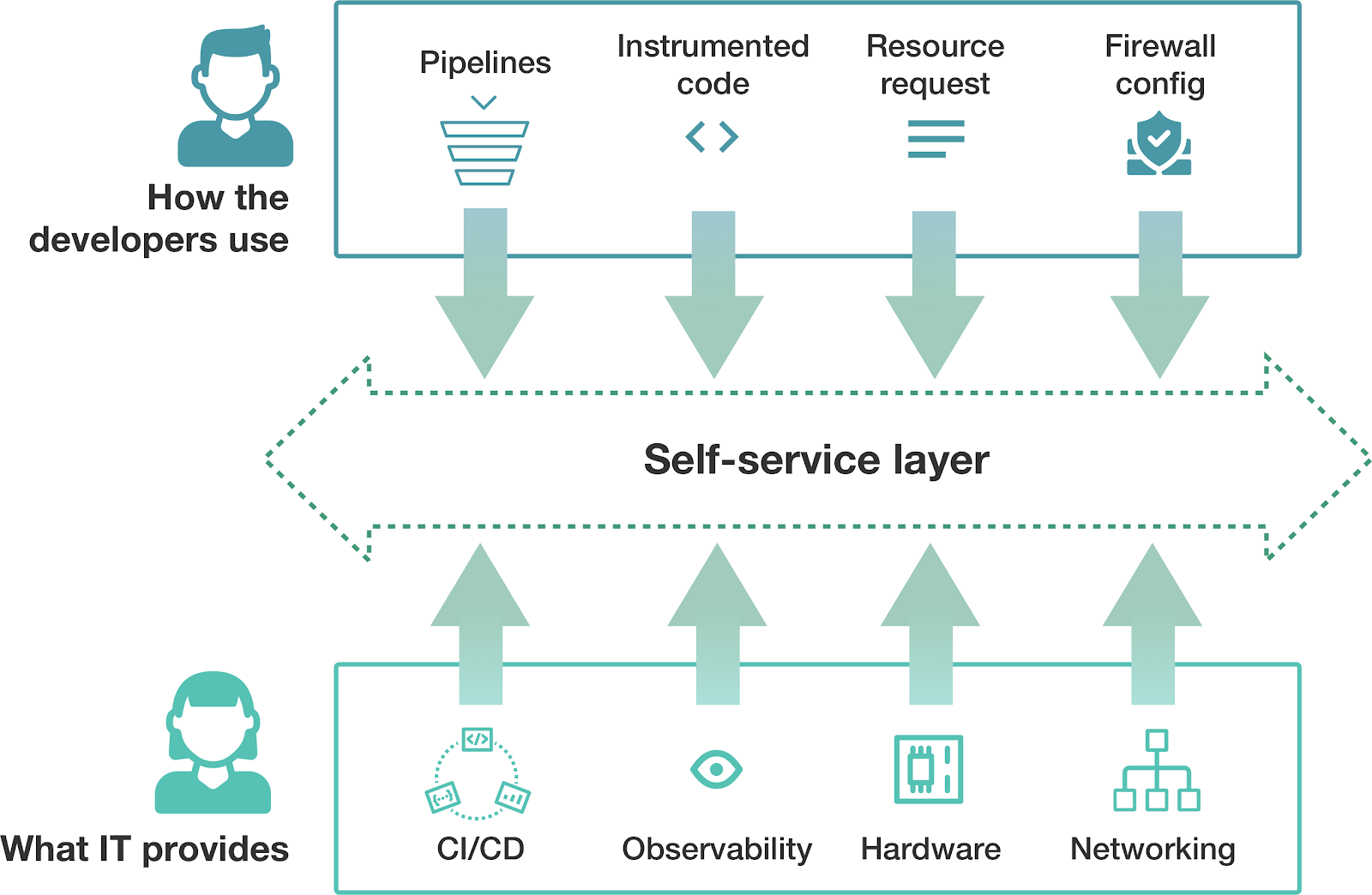
The image above covers a few of the functionalities most companies will have in their self-service platform. IT provides tools and processes for core functionalities, focusing on providing a solid foundation. Meanwhile, developers define customizations on top of the platform or perform integration for their particular application. Companies have been reducing the distance between developers and operators for many years now, which allowed lower-level constructs to be used. However, that is not enough for researchers.
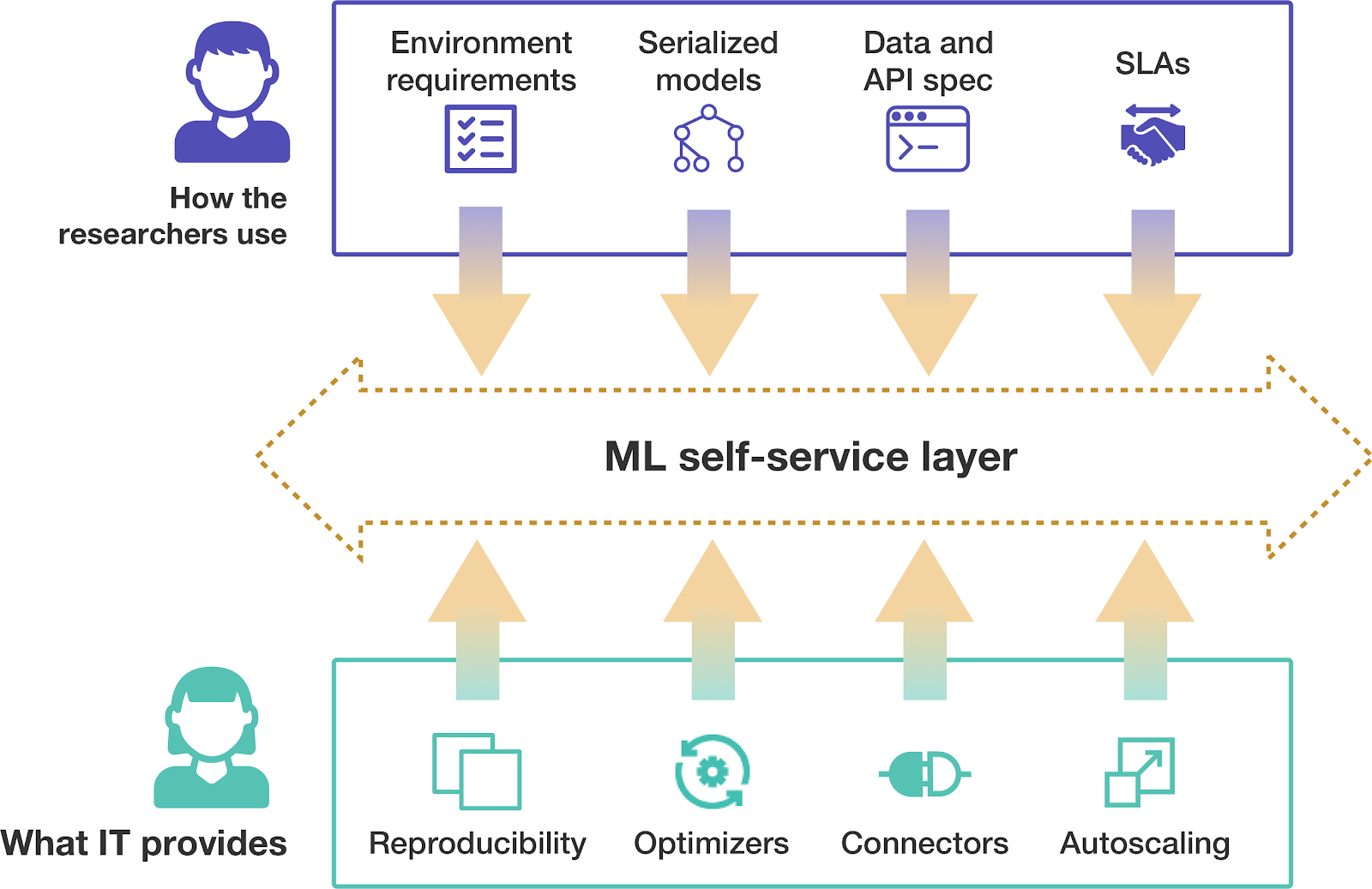
As we have argued before, data scientists' current skill set is very distinct from bringing up and operating one of their models in production. Hence the platform provided for researchers needs to be at a higher level than for software developers. For example, developers know how to define their systems' behavior to ensure it meets a particular SLA. But data scientists want to specify what those SLAs are and rely on a platform to handle the complexities to achieve that.
Thankfully the industry started to make higher-level constructs available for software engineers too. As anybody would suspect, operating low-level definitions is a considerable overhead. However, the further away you get from the specifics, the more domain knowledge you need to embed in the platform. Unfortunately, not every operations team has this knowledge at hand to support ML applications.
MLOps challenge 4: adapt to existing processes and grow with the company
Every big software company has a set of processes in place for software development. These processes took years and many iterations to develop correctly, potentially including expensive mistakes. When thinking about using models in production, teams frequently face the challenge of building these processes from scratch.
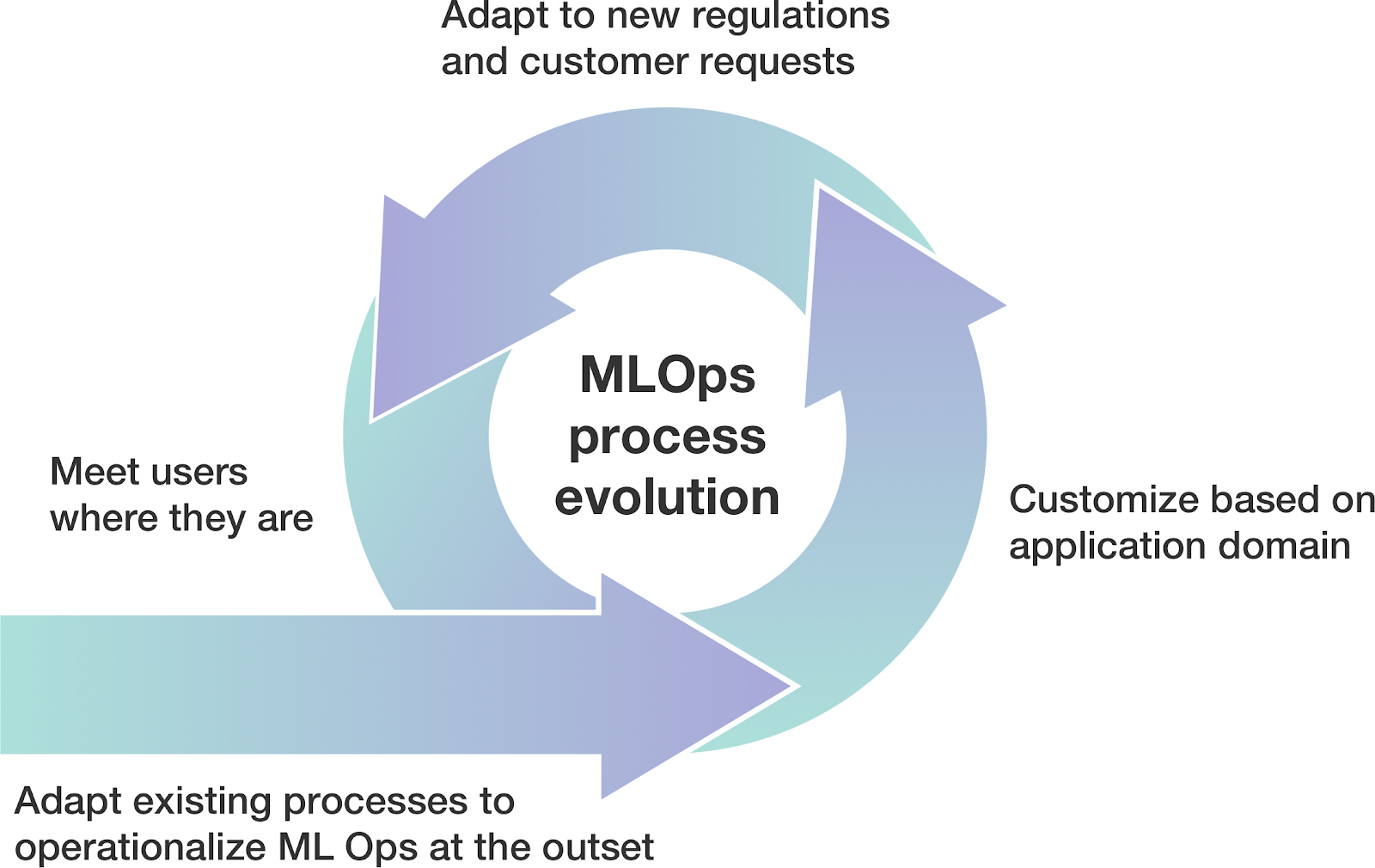
However, at the start of the ML journey, most operations constraints will look similar to doing software engineering. Operationalizing ML has higher success at places that first adapt their current processes the best they can. Once they have that initial version, the team iterates on the process as they identify improvements related to the new application domain or new product requirements.
This evolution of processes means that platforms and infrastructure must be able to adapt along with their teams. As new regulations and customer requests evolve, so will the requirements and limitations on model development and execution. Switching to a new system every time that happens is expensive. But relying on external enforcement is prone to misalignment failures. Hence production ML needs to meet users where they are today to bring immediate value while supporting the evolution of their ML methodologies.
MLOps challenge 5: new layer at the operations stack
This challenge is potentially the most undervalued one for MLOps: adding models creates an entirely new layer to the operations stack. In a simplified way, each level of the operation stack covers the unit of computation, how things communicate, and how they ensure they are talking about the same thing.
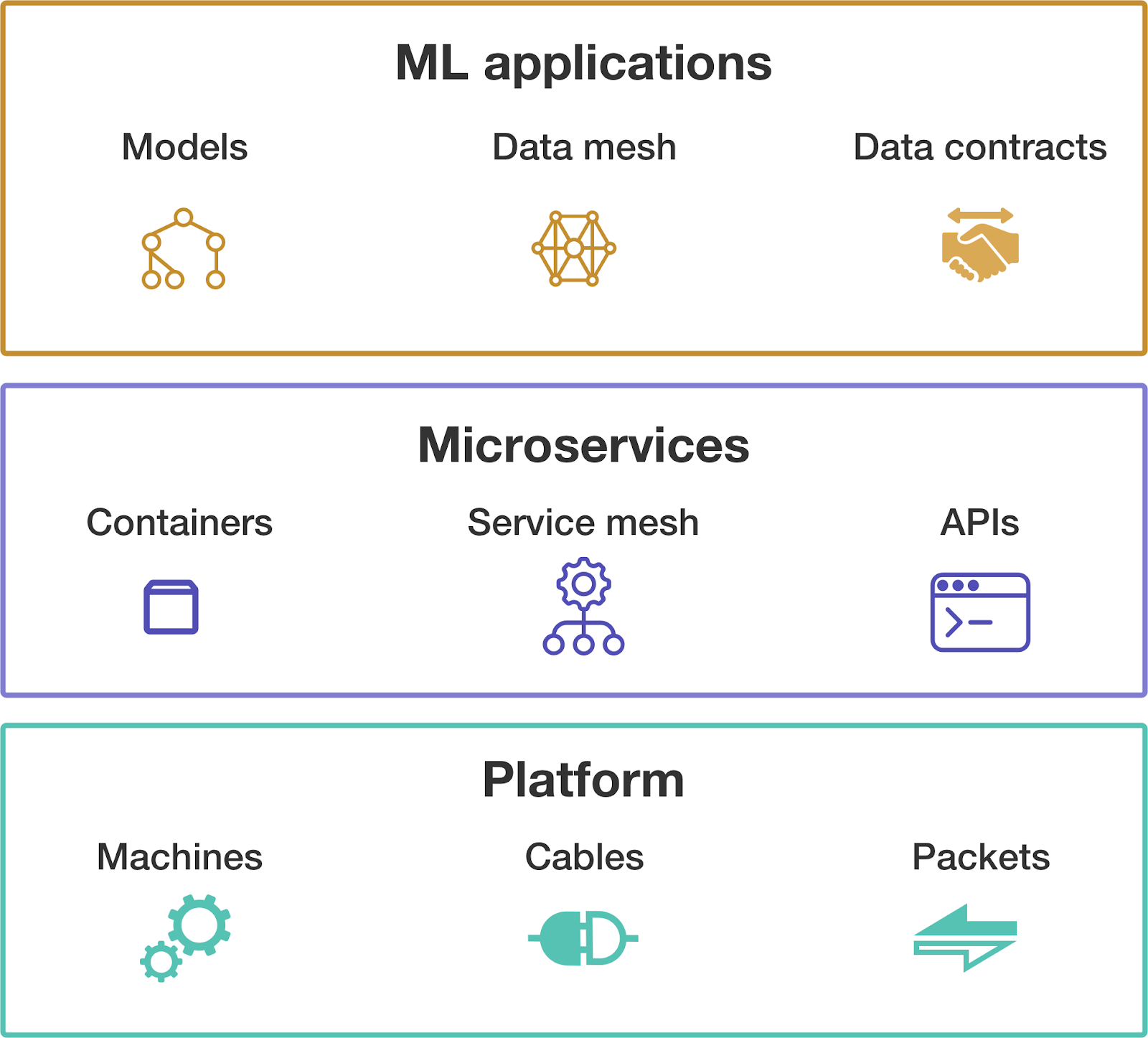
The image below shows the well-known physical and distributed layers. In the physical, we're mainly focused on concrete elements. We're talking about machines with network cables and communicating via packets. The main failure modes include lost packets, machines going down, and incorrect routing, among many others. But this layer gives enough flexibility to build more complex systems.
The next one comes when we have numerous services decoupled from each other and changing over time. The concern becomes the structure of these pieces and their communication. Note that the two levels of the stack are not mutually exclusive; you can adopt partial solutions and mix them. But when you go down a level, you lose some features.
We have seen a considerable growth of this second layer in recent years as the microservices ecosystem became more mature. You have robust service meshes and container orchestration, and you design your API with versions and backward compatibility to prevent others. This abstraction brings enough benefits that tools like Kubernetes, Envoy, and gRPC became the core of a modern infrastructure stack.
Now we're entering a new level with ML applications. The concern is one level above the structure: the content of the data itself is critical. We are not only concerned if the server and client APIs match, but also if their data distributions are compatible. ML models are known to operate well within some boundaries of their training data, but badly outside. The wrong data distribution in the input can be as catastrophic as an unavailable service if we can even monitor it.
This new layer means we need a completely new toolset on top of what we already have today. The same operation concerns that led to the development of general functionality at the physical and distributed levels drive the need to observe at the data level. Getting this application layer to an integrated state will be crucial to making ML just another component of your product.
Introducing Verta: an MLOps platform for production ML
At Verta, we’re building a platform to help companies extract value from their models in an agile and automated way.
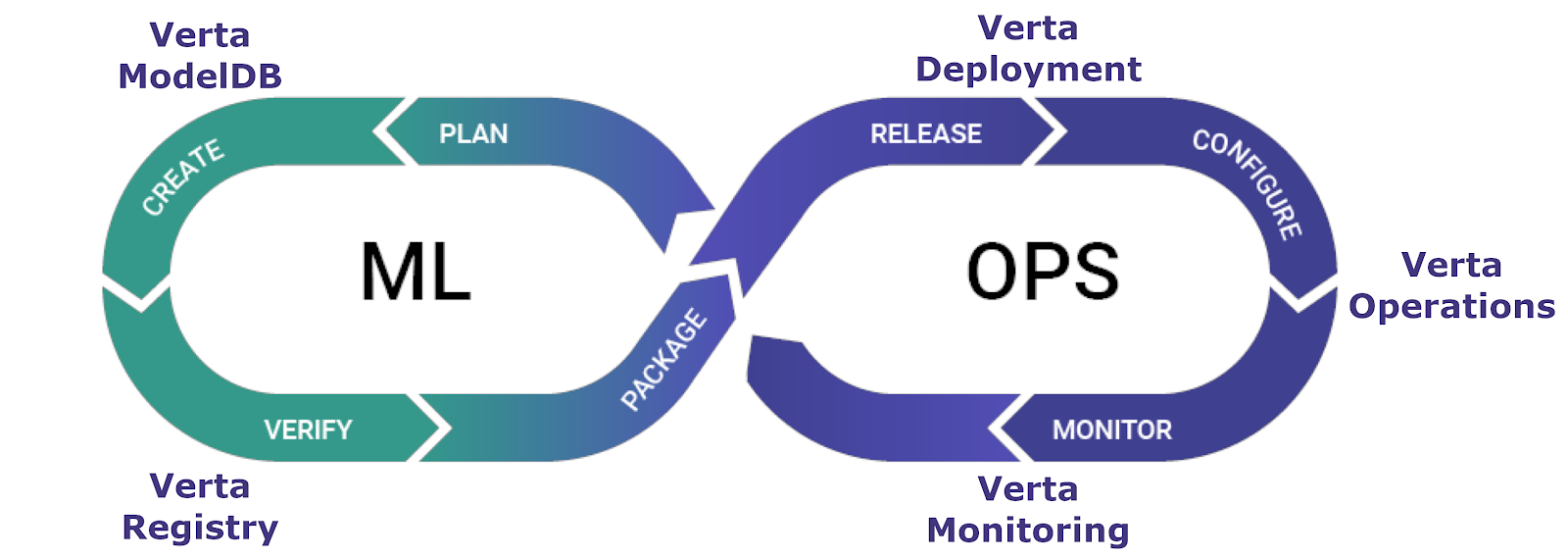
At a high level, the Verta Platform includes:
- ModelDB, the first model management system, for versioning and tracking of your ML work;
- Registry for managing production versions and approval flows;
- Deployment for packaging, configuring and safely deploying models;
- Operations for providing autopilot for models to satisfy SLAs;
- Monitoring for observability of the new stack;
- WebApp and SDK for managing the whole workflow and resources.
As we have highlighted, being able to integrate with existing solutions is critical for MLOps bootstrapping. Every component of our platform can be integrated into existing solutions via their comprehensive APIs.
We’re currently in production with tech companies and partnering closely with others to make their ML goals a reality. If your team faces similar challenges and is interested in a partnership, we’d love to chat!
We’re also continually looking for talent to join us as the demand increases. If you want to work on challenging projects, and be at the edge of making ML a reality in products, check out our jobs page!
Subscribe To Our Blog
Get the latest from Verta delivered directly to you email.


